
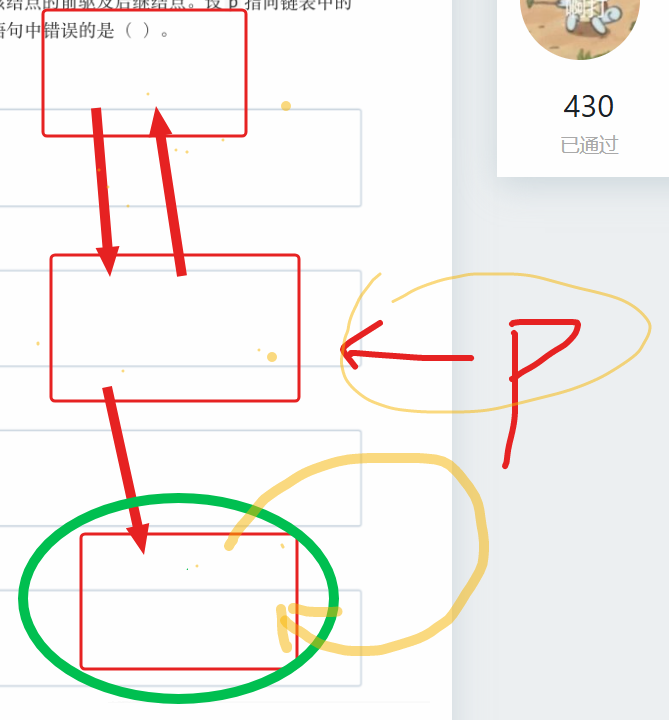
要删除双向链表中节点 p(其前驱和后继均非空 ),需让 p 的前驱节点的 next 指向 p 的后继节点,同时让 p 的后继节点的 prev 指向 p 的前驱节点,最后 delete p 释放内存。
选项分析
- A选项:
p->next->prev = p->next;错误,这会让p后继节点的prev指向自身,无法正确连接前后节点,无法完成删除逻辑。 - B选项:先让
p前驱节点的next指向p后继节点,再让p后继节点的prev指向p前驱节点,最后delete p,逻辑正确。 - C选项:先让
p后继节点的prev指向p前驱节点,再通过p->next->prev->next = p->next;让p前驱节点的next指向p后继节点,最后delete p,逻辑正确。 - D选项:先让
p前驱节点的next指向p后继节点,再通过p->prev->next->prev = p->prev;让p后继节点的prev指向p前驱节点,最后delete p,逻辑正确。
答案选 A 。
20 条评论
-
admin SU @ 2025-6-19 21:20:33
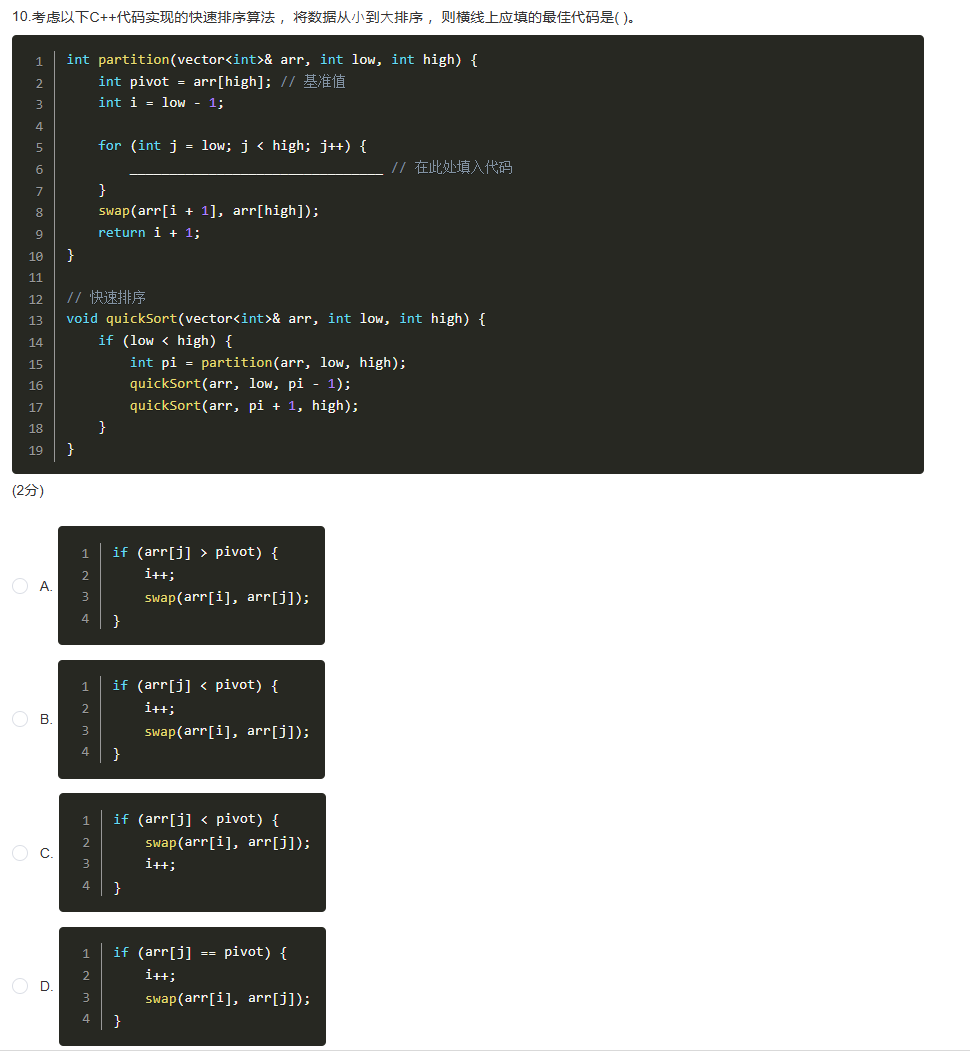
答案为B。
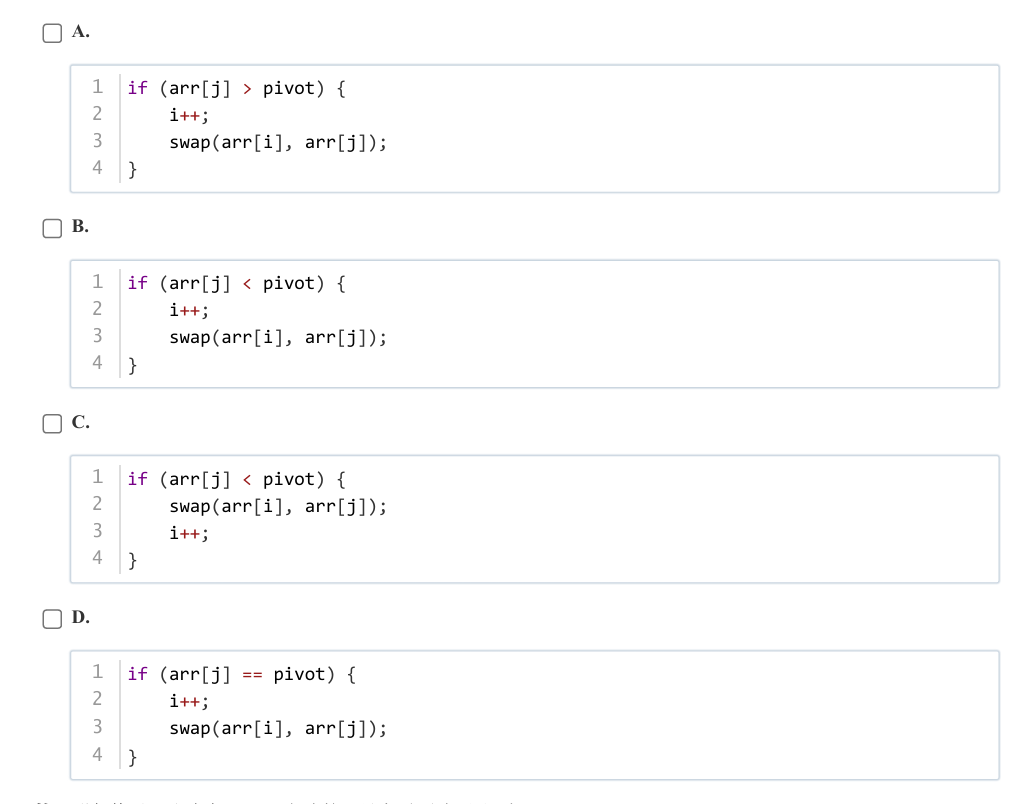
快速排序的
partition函数中,要将小于基准值pivot(这里pivot = arr[high])的元素放到左边,所以当arr[j] < pivot时,i先自增,再交换arr[i]和arr[j],B选项符合快速排序升序排列时partition函数的逻辑 。 -
@ 2025-6-19 21:19:01

答案为A。
选择排序在排序过程中会进行不相邻元素的交换,可能导致相同值元素的相对位置改变,是不稳定排序;插入排序、归并排序、冒泡排序在合理实现下能保证相同值元素相对位置不变,是稳定排序 。
-
@ 2025-6-19 21:18:31
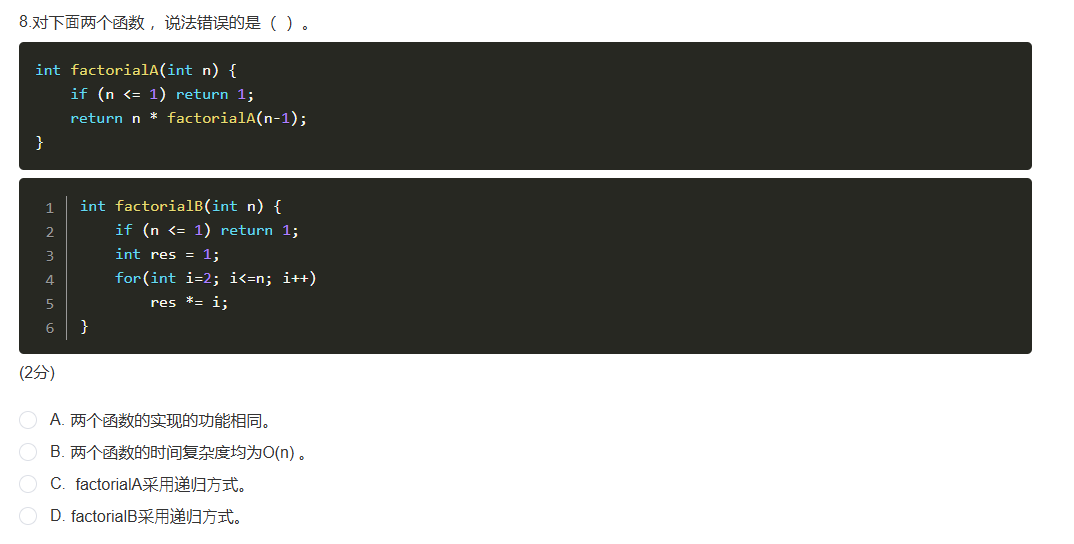
答案为 D 。
factorialA函数自己调用自己,是递归方式;factorialB函数通过for循环实现,是迭代方式,并非递归,A选项两函数都实现阶乘功能,B选项时间复杂度均为 (O(n)) ,C选项factorialA是递归,所以说法错误的是D。 -
@ 2025-6-19 21:15:44

答案为 D 。
factorialA函数自己调用自己,是递归方式;factorialB函数通过for循环实现,是迭代方式,并非递归,A选项两函数都实现阶乘功能,B选项时间复杂度均为 (O(n)) ,C选项factorialA是递归,所以说法错误的是D。 -
@ 2025-6-19 21:09:33

答案为A。
在程序中,递归调用是通过栈(stack)来实现的,每一次递归调用都会在栈中分配一块空间来保存当前调用的状态等信息,当递归调用层数过多时,栈空间会被耗尽,即系统分配的栈空间溢出,引发错误 ;堆(heap)主要用于动态分配内存,队列(queue)常用于实现队列相关操作,链表(linked list)是一种数据结构,均与递归调用层数过多引发错误的原因无关。
-
@ 2025-6-9 21:54:10

详细解析
第1题
题目: 单链表中删除某个结点p(非尾结点),但不知道头结点,可行的操作是将p的值设为p->next的值,然后删除p->next。
答案:√
解析:
- 在单链表中,如果要删除一个节点p且不通过头结点访问,可以采用以下步骤:
- 将p节点的值替换为p->next节点的值。
- 删除p->next节点。
- 这样操作后,原p节点就变成了p->next节点,而p->next节点被删除,从而实现了删除p节点的效果。因此该说法正确。
第2题
题目: 链表存储线性表时要求内存中可用存储单元地址是连续的。
答案:×
解析:
- 链表是一种动态数据结构,其节点在内存中的存储位置不需要连续。
- 每个节点包含数据和指向下一个节点的指针,通过指针链接各个节点,实现数据的顺序存储。
- 因此,链表不要求内存中存储单元地址连续,与数组等静态数据结构不同。
第3题
题目: 线性筛相对于埃拉托斯特尼筛法,每个合数只会被它的最小质因数筛去一次,因此效率更高。
答案:√
解析:
- 线性筛(欧拉筛)优化了埃拉托斯特尼筛法,确保每个合数只被其最小质因数筛除一次。
- 这种方法避免了重复筛除,时间复杂度为O(n),比埃拉托斯特尼筛法的O(n log log n)更高效。
第4题
题目: 贪心算法通过每一步选择当前最优解,从而一定能获得全局最优解。
答案:×
解析:
- 贪心算法每次选择局部最优解,但并不保证最终结果是全局最优解。
- 贪心算法适用于某些特定问题,如活动选择、哈夫曼编码等,但在其他问题中可能无法得到最优解。
第5题
题目: 递归函数必须具有一个终止条件,以防止无限递归。
答案:√
解析:
- 递归函数通过调用自身解决问题,必须设置终止条件来结束递归过程。
- 如果没有终止条件,递归会无限进行,导致栈溢出错误。
第6题
题目: 快速排序算法的时间复杂度与输入是否有序无关,始终稳定为O(nlogn)。
答案:×
解析:
- 快速排序算法的时间复杂度与输入数据有关。
- 最好情况下时间复杂度为O(nlogn),最坏情况下(如已排序或逆序排列)时间复杂度为O(n²)。
- 平均时间复杂度为O(nlogn),但不稳定。
第7题
题目: 归并排序算法的时间复杂度与输入是否有序无关,始终稳定为O(nlogn)。
答案:√
解析:
- 归并排序是一种分治算法,无论输入数据如何,其时间复杂度均为O(nlogn)。
- 它通过不断分割和合并子数组,确保每次合并操作的时间复杂度为O(n),总复杂度为O(nlogn)。
第8题
题目: 二分查找适用于对无序数组和有序数组的查找。
答案:×
解析:
- 二分查找要求数组必须是有序的,才能通过中间值比较快速缩小查找范围。
- 对于无序数组,应使用顺序查找或其他适合的方法。
第9题
题目: 小杨有100元去超市买东西,每个商品有各自的价格,每种商品只能买1个,小杨的目标是买到最多数量的商品。小杨采用的策略是每次挑价格最低的商品买,这体现了分治思想。
答案:×
解析:
- 小杨的策略属于贪心算法,每次选择价格最低的商品,以最大化购买数量。
- 分治思想是将大问题分解成若干个小问题分别解决,再合并结果,与本题策略不符。
第10题
题目: 归并排序算法体现了分治算法,每次将大的待排序数组分成大小大致相等的两个小数组,然后分别对两个小数组进行排序,最后对排好序的两个小数组合并成有序数组。
答案:√
解析:
- 归并排序正是基于分治思想,将大数组不断分割成小数组,分别排序后再合并。
- 这种方法确保了每次合并操作都能得到有序数组,最终完成整个数组的排序。
这是一组数据结构与算法相关的判断题及答案,以下是对各题判断依据的快速梳理:
- 第1题:单链表非尾节点删除,无表头时,复制后继值再删后继,操作可行,正确。
- 第2题:链表存储不要求内存连续,依靠指针连接,错误。
- 第3题:线性筛(欧拉筛)利用最小质因数保证合数仅筛一次,效率高于埃氏筛,正确。
- 第4题:贪心选当前最优,未必得全局最优(如背包问题),错误。
- 第5题:递归若无终止条件会无限递归,必须有,正确。
- 第6题:快速排序最坏(有序)时是 (O(n^2)),并非始终 (O(n\log n)) ,错误。
- 第7题:归并排序时间复杂度稳定 (O(n\log n)),与输入无关,正确。
- 第8题:二分查找仅适用于有序数组,错误。
- 第9题:选价格最低商品是贪心,非分治(分治需分解子问题再合并),错误。
- 第10题:归并排序将数组分治、递归排序子数组再合并,体现分治思想,正确。
答案已在题干给出,若需验证或解析某题,可进一步说明 。
- 在单链表中,如果要删除一个节点p且不通过头结点访问,可以采用以下步骤:
-
@ 2025-6-9 21:53:09

-
@ 2025-6-9 21:52:54
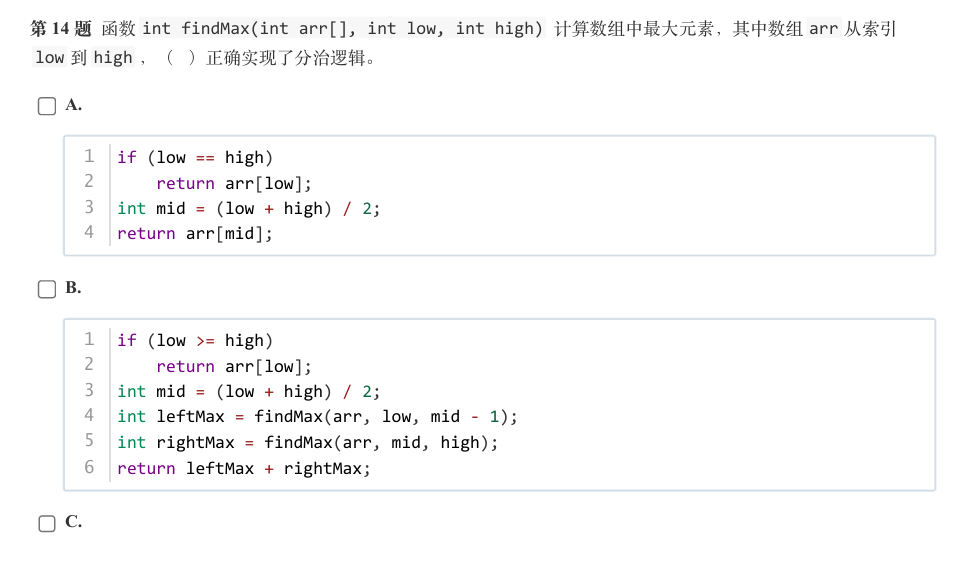

-
@ 2025-6-9 21:52:25

-
@ 2025-6-9 21:52:11
-
@ 2025-6-9 21:51:47

-
@ 2025-6-9 21:51:23

-
@ 2025-6-9 21:50:23

-
@ 2025-6-9 21:50:11

-
@ 2025-6-9 21:49:55

-
@ 2025-6-9 21:49:29

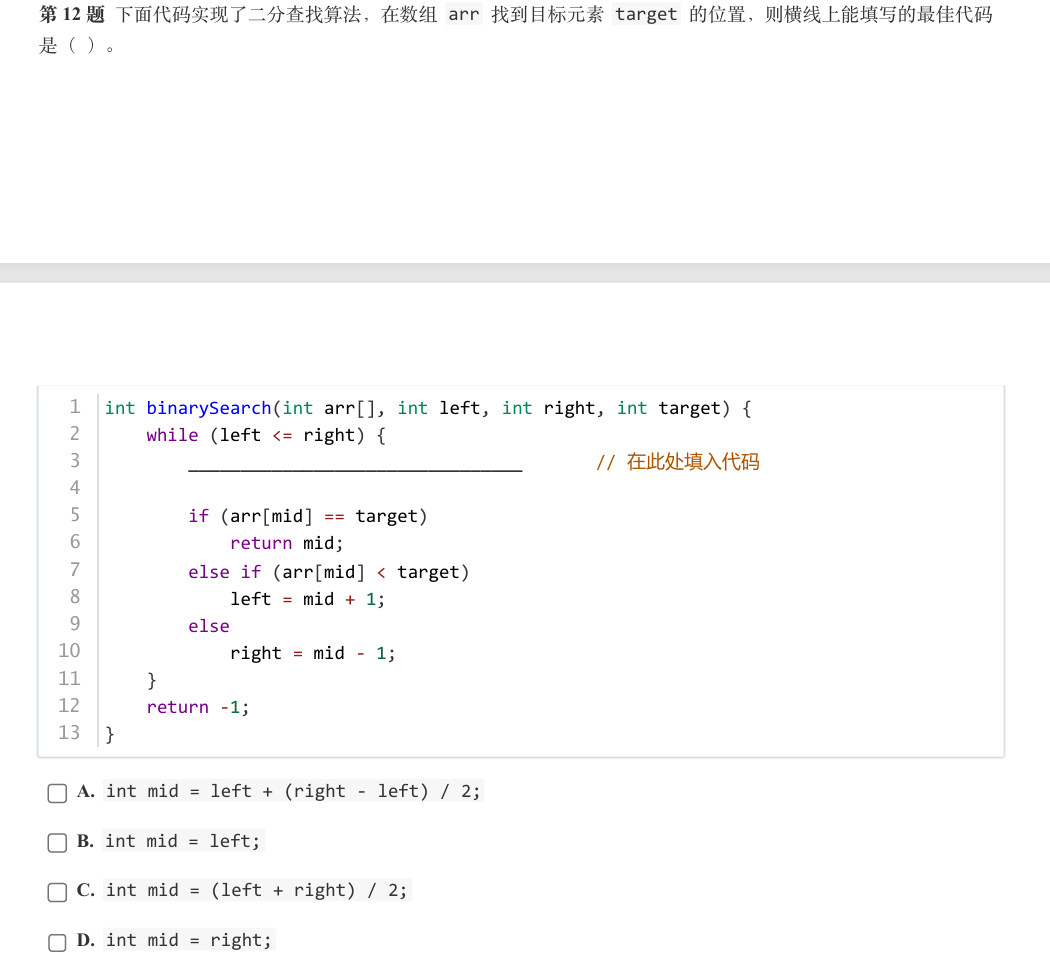
 本题考查线性筛法(欧拉筛)的代码逻辑,核心是控制筛除标记的循环条件。
本题考查线性筛法(欧拉筛)的代码逻辑,核心是控制筛除标记的循环条件。线性筛法需同时满足:
- 遍历已找到的素数:通过
j < primes.size()保证遍历到primes中存储的所有素数。 - 筛除范围有效:通过
i * primes[j] <= n保证标记的合数不超过题目要求的范围n。
- A 仅遍历素数,没限制筛除范围,可能越界。
- B 仅限制范围,没控制素数遍历,会访问非法下标。
- C 同时满足“遍历素数数组”和“筛除范围不超
n”,符合线性筛法逻辑。 - D 条件无意义,
j是素数数组下标,与n无直接关联。
答案:C
- 遍历已找到的素数:通过
-
@ 2025-6-9 21:47:52

唯一分解定理要求将整数分解为素数(质数)的乘积。
- A选项:
6不是素数(6 = 2×3),分解不彻底。 - B选项:
4不是素数(4 = 2×2),分解不彻底。 - C选项:
6不是素数(6 = 2×3),分解不彻底。 - D选项:
2、3、5均为素数,符合唯一分解定理。
答案:D
- A选项:
-
@ 2025-6-9 21:47:06
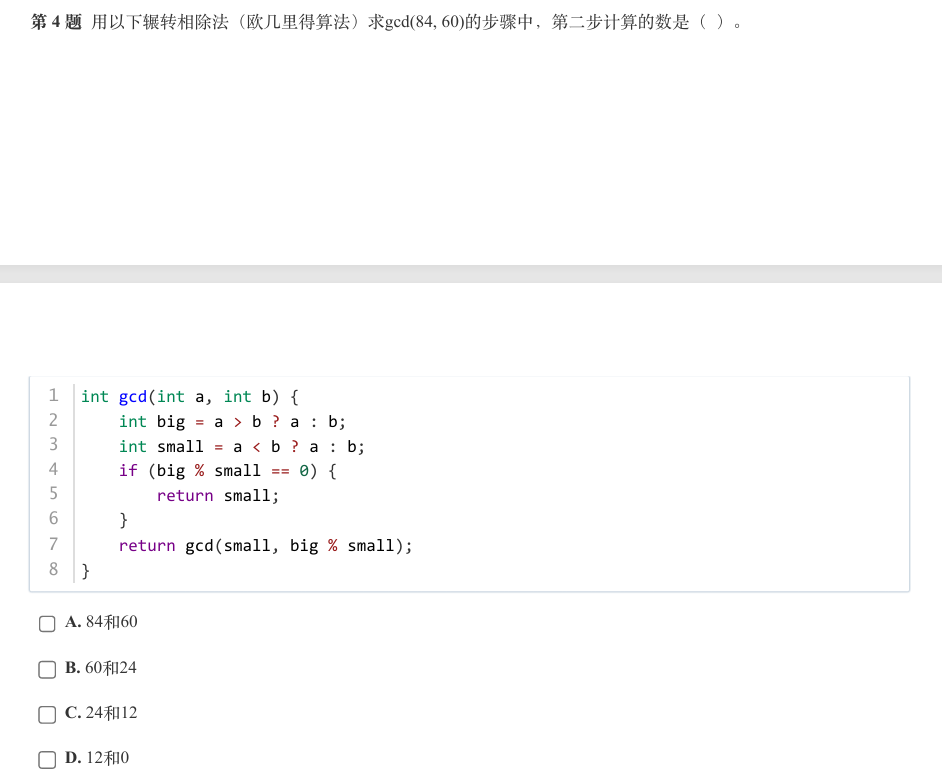
- 首先分析
gcd(84, 60)的第一步:- 调用
gcd(84, 60),big = 84,small = 60。因为84 % 60 = 24≠0,所以递归调用gcd(60, 24)。
- 调用
- 第二步就是
gcd(60, 24)这一步的调用,此时计算的数是60和24。
答案是B。
- 首先分析
-
@ 2025-6-9 21:45:48

答案为 A 。
解析:
链表是通过指针连接节点,要访问某个元素需从头节点依次遍历,不能随机访问(随机访问是数组特点,可通过下标直接访问);B 选项,链表插入、删除只需改指针,无需移动元素,是链表特点;C 选项,链表动态分配内存,无需预先估计存储空间,是特点;D 选项,链表每个节点存数据和指针,存储空间与元素个数成正比,是特点 。所以链表不具备的特点是 A 。
-
@ 2025-6-9 21:44:57

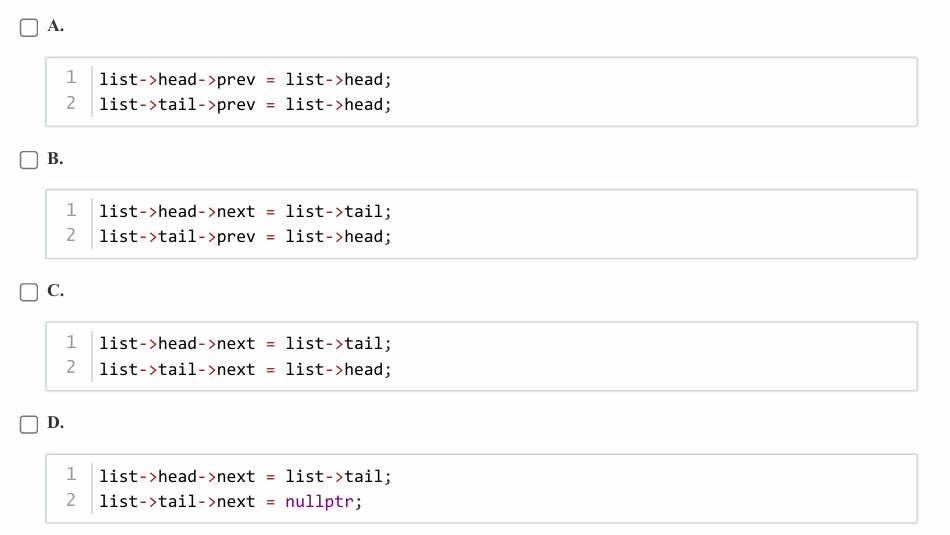
要构建双向循环链表(含头尾哨兵节点),需让头节点的
next指向尾节点,尾节点的prev指向头节点,同时尾节点的next指向头节点、头节点的prev指向尾节点 ,形成循环。但本题场景是先连接头尾基本关联,代码里已创建head和tail节点,需补全让链表成双向循环的指针连接。选项分析
- A选项:
list->head->prev = list->head;让头节点前驱指向自身,破坏双向循环逻辑;list->tail->prev = list->head;仅处理尾节点前驱,未正确连接头节点后继,错误。 - B选项:
list->head->next = list->tail;让头节点后继指向尾节点,list->tail->prev = list->head;让尾节点前驱指向头节点,完成双向链表基础连接,但因是循环链表,还需让list->tail->next = list->head、list->head->prev = list->tail才完整。不过本题是构建“空的双向循环链表”初始连接,这两步是核心基础,先完成头 - 尾、尾 - 头的双向连接 ,该选项是构建双向循环链表的必要部分,暂时保留。 - C选项:
list->head->next = list->tail;头节点后继指向尾节点,list->tail->next = list->head;尾节点后继指向头节点,仅处理了next方向循环,未处理prev方向,不是完整双向循环,错误。 - D选项:
list->tail->next = nullptr;让尾节点后继为空,不符合循环链表“尾节点后继指向头节点”的要求,错误。
结合双向循环链表定义,正确构建需头节点
next连尾节点、尾节点prev连头节点,同时尾节点next连头节点、头节点prev连尾节点 。但本题代码是初始化空链表,先完成头和尾的双向基础连接(头next连尾、尾prev连头 )是关键,后续循环的另一部分(头prev连尾、尾next连头 )通常也需补充,不过看选项,B是构建双向循环链表初始连接的必要正确步骤(完整双向循环还需后续补充,但题目选项里它是构建双向关联的正确基础 ),答案选 B 。严格说,完整双向循环链表需:
list->head->next = list->tail; list->tail->prev = list->head; list->tail->next = list->head; list->head->prev = list->tail;但题目选项中,B是实现双向连接的关键第一步,是本题最佳答案。
- A选项:
- 1