素数(质数)是指一个大于 1 且除了 1 和它自身外,不能被其他自然数整除的数。埃氏筛法(埃拉托斯特尼筛法)和线性筛法(欧拉筛法)是两种常见的用于生成素数表的算法,下面分别介绍这两种算法及其 C++ 实现。
埃氏筛法
算法原理
埃氏筛法的基本思想是从 2 开始,将每个素数的倍数标记为合数,直到遍历完所有小于等于给定上限的数。因为如果一个数是素数,那么它的倍数一定是合数。
代码实现
#include <iostream>
#include <vector>
std::vector<bool> sieveOfEratosthenes(int n) {
// 创建一个布尔类型的向量,初始值都为 true,表示所有数都是素数
std::vector<bool> isPrime(n + 1, true);
// 0 和 1 不是素数
isPrime[0] = isPrime[1] = false;
for (int i = 2; i * i <= n; ++i) {
if (isPrime[i]) {
// 将 i 的倍数标记为合数
for (int j = i * i; j <= n; j += i) {
isPrime[j] = false;
}
}
}
return isPrime;
}
int main() {
int n = 30;
std::vector<bool> isPrime = sieveOfEratosthenes(n);
std::cout << "小于等于 " << n << " 的素数有: ";
for (int i = 2; i <= n; ++i) {
if (isPrime[i]) {
std::cout << i << " ";
}
}
std::cout << std::endl;
return 0;
}
复杂度分析
- 时间复杂度:。这是因为对于每个素数 ,需要标记 个数为合数,而 $\sum_{p \leq n} \frac{n}{p} = n \sum_{p \leq n} \frac{1}{p}$,其中 。
- 空间复杂度:,主要用于存储布尔类型的数组。
线性筛法
算法原理
线性筛法的核心思想是让每个合数只被它的最小质因子筛去,从而保证每个数只被标记一次,达到线性的时间复杂度。
代码实现
#include <iostream>
#include <vector>
std::vector<int> eulerSieve(int n) {
std::vector<bool> isPrime(n + 1, true);
std::vector<int> primes;
for (int i = 2; i <= n; ++i) {
if (isPrime[i]) {
primes.push_back(i);
}
for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) {
isPrime[i * primes[j]] = false;
if (i % primes[j] == 0) {
break;
}
}
}
return primes;
}
int main() {
int n = 30;
std::vector<int> primes = eulerSieve(n);
std::cout << "小于等于 " << n << " 的素数有: ";
for (int prime : primes) {
std::cout << prime << " ";
}
std::cout << std::endl;
return 0;
}
复杂度分析
- 时间复杂度:,因为每个数只会被它的最小质因子筛去一次。
- 空间复杂度:,主要用于存储布尔类型的数组和素数数组。
两种算法的比较
- 埃氏筛法实现简单,但存在重复标记的问题,时间复杂度相对较高。
- 线性筛法通过避免重复标记,达到了线性的时间复杂度,效率更高,但实现相对复杂一些。在处理大规模数据时,线性筛法更具优势。
23 条评论
-
admin SU @ 2025-6-19 20:57:38
#include <iostream> #include <vector> using namespace std; vector<int> eulerSieve(int n) { vector<bool> isPrime(n + 1, true); vector<int> primes;//vector<int> primes = eulerSieve(n); for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); } for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; if (i % primes[j] == 0) { break; } } } return primes; } int main() { int n = 30; cin >> n; vector<int> primes = eulerSieve(n); cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { cout << prime << " "; } cout << endl; return 0; } -
@ 2025-6-19 20:27:30
#include <iostream> #include <vector> #include <cmath> using namespace std; vector<bool> sieveOfEratosthenes(int n) { // 创建一个布尔类型的向量,初始值都为 true,表示所有数都是素数 vector<bool> isPrime(n + 1, true); // 0 和 1 不是素数 isPrime[0] = isPrime[1] = false; for (int i = 2; i <= sqrt(n); ++i) { if (isPrime[i] == true) { // 将 i 的倍数标记为合数 for (int j = i*i; j <= n; j += i) { isPrime[j] = false; } } } return isPrime; } int main() { int n = 30; cin>>n; vector<bool> isPrime = sieveOfEratosthenes(n); cout << "小于等于 " << n << " 的素数有: "; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { cout << i << " "; } } cout << endl; return 0; } -
@ 2025-6-19 20:08:17
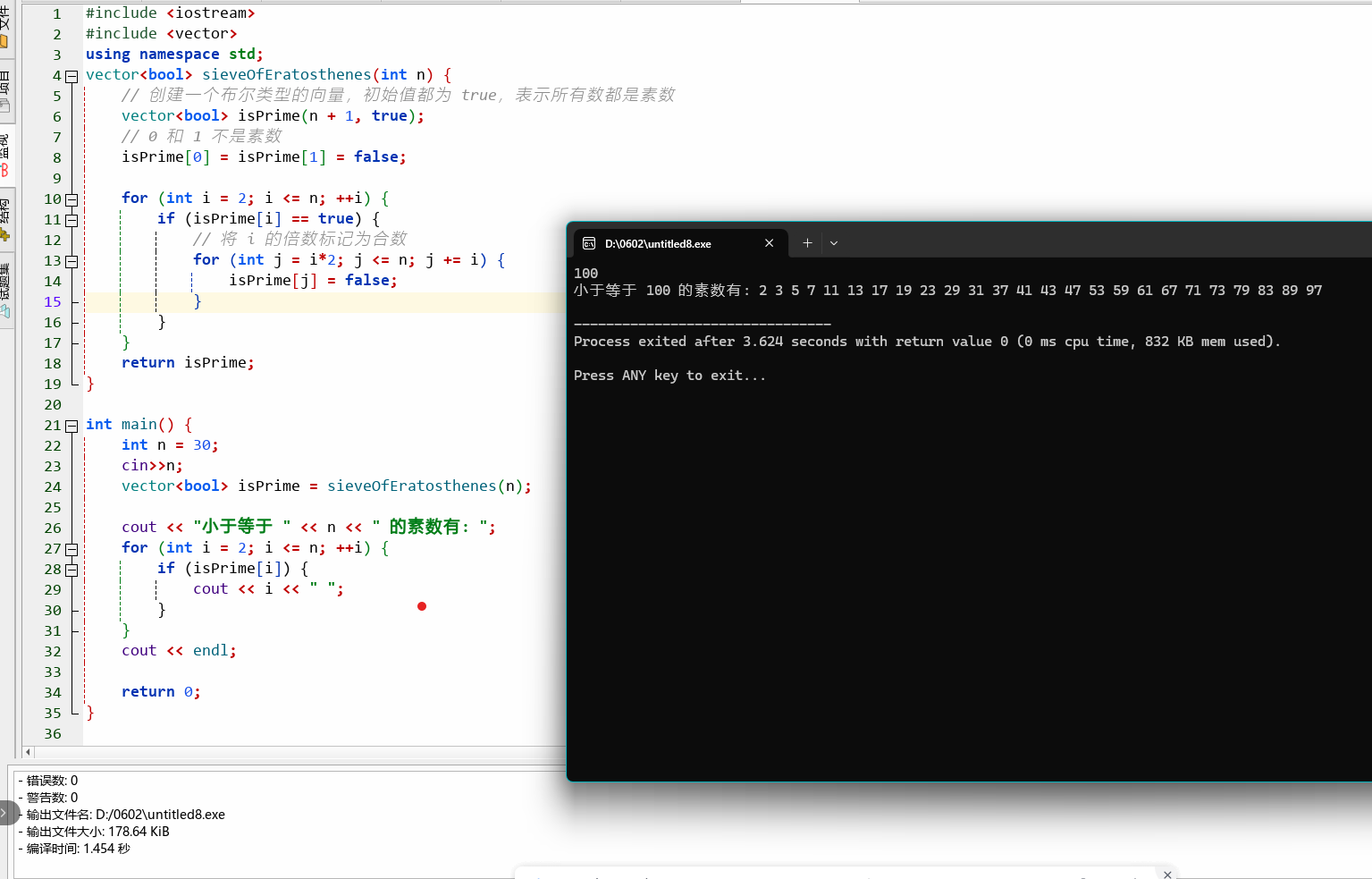
#include <iostream> #include <vector> using namespace std; vector<bool> sieveOfEratosthenes(int n) { // 创建一个布尔类型的向量,初始值都为 true,表示所有数都是素数 vector<bool> isPrime(n + 1, true); // 0 和 1 不是素数 isPrime[0] = isPrime[1] = false; for (int i = 2; i <= n; ++i) { if (isPrime[i] == true) { // 将 i 的倍数标记为合数 for (int j = i*2; j <= n; j += i) { isPrime[j] = false; } } } return isPrime; } int main() { int n = 30; cin>>n; vector<bool> isPrime = sieveOfEratosthenes(n); cout << "小于等于 " << n << " 的素数有: "; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { cout << i << " "; } } cout << endl; return 0; } -
@ 2025-6-16 22:04:10
埃拉托斯特尼筛法(Sieve of Eratosthenes)和线性筛(欧拉筛,Sieve of Euler)的核心区别在于合数被标记的方式和时间复杂度。虽然两者都能保证每个合数被其最小素因子筛掉,但实现细节和效率不同。
核心区别对比
特性 埃拉托斯特尼筛法 线性筛(欧拉筛) 标记策略 每个素数 p标记其所有倍数p², p²+p, ...每个数 i与其最小素因子min_prime[i]结合,标记i × min_prime[j](j ≤ min_prime[i])合数被标记次数 可能被多次标记(如 30被2, 3, 5各标记一次)仅被其最小素因子标记一次(如 30仅被2标记)时间复杂度 O(n log log n) O(n)(线性时间) 空间复杂度 O(n) 适用场景 中小范围素数筛选(如 n ≤ 1e7)大范围素数筛选(如 n ≥ 1e7)或需要最小素因子数组的场景埃拉托斯特尼筛法的局限性
- 重复标记:当一个合数有多个素因子时,会被多次访问。例如:
30被2(2 × 15)、3(3 × 10)、5(5 × 6)各标记一次。- 时间复杂度 O(n log log n) 源于调和级数的近似:Σ(1/p) ≈ log log n(对所有素数
p ≤ n)。
线性筛的优化原理
线性筛通过每个合数仅被其最小素因子筛一次来达到线性时间:
- 维护最小素因子数组
min_prime[]:记录每个数的最小素因子。 - 标记规则:
对于每个数i,遍历已找到的素数列表primes,标记i × primes[j]为合数,直到primes[j]是i的最小素因子。for (int j = 0; j < primes.size() && primes[j] <= min_prime[i]; j++) { min_prime[i × primes[j]] = primes[j]; }- 例如:当
i = 15(最小素因子为3),则标记15 × 2 = 30(最小素因子为2),但不标记15 × 3 = 45(因3是15的最小素因子,需停止以避免重复)。
- 例如:当
代码对比
埃拉托斯特尼筛法
std::vector<bool> sieveOfEratosthenes(int n) { std::vector<bool> isPrime(n + 1, true); isPrime[0] = isPrime[1] = false; for (int i = 2; i * i <= n; ++i) { if (isPrime[i]) { for (int j = i * i; j <= n; j += i) { isPrime[j] = false; // 可能重复标记 } } } return isPrime; }线性筛(欧拉筛)
std::vector<int> sieveOfEuler(int n) { std::vector<bool> isPrime(n + 1, true); std::vector<int> primes; std::vector<int> min_prime(n + 1, 0); // 记录最小素因子 for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); min_prime[i] = i; } for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; min_prime[i * primes[j]] = primes[j]; if (primes[j] == min_prime[i]) break; // 关键优化 } } return primes; }关键优化点
-
线性时间的保证:
线性筛通过if (primes[j] == min_prime[i]) break;确保每个合数仅被其最小素因子筛一次。例如:i = 6(最小素因子为2),标记6 × 2 = 12后停止,避免6 × 3 = 18(18应由9 × 2标记,以确保被2筛出)。
-
最小素因子数组的用途:
线性筛同时生成min_prime[]数组,可用于快速分解质因数(时间复杂度 O(log n))。
总结
- 埃拉托斯特尼筛法:简单易实现,适用于中小范围,时间复杂度 O(n log log n),合数可能被多次标记。
- 线性筛:通过精细控制标记规则,达到线性时间 O(n),每个合数仅被筛一次,且可额外生成最小素因子数组,适用于大范围筛选或需要质因数分解的场景。
- 重复标记:当一个合数有多个素因子时,会被多次访问。例如:
-
@ 2025-6-16 21:57:12
在埃拉托斯特尼筛法中,将外层循环条件从
i * i <= n优化为i <= n的原理涉及算法的核心逻辑和数学性质。以下是详细解释:优化原理
埃拉托斯特尼筛法的核心是:对于每个素数
p,标记其所有倍数p², p²+p, p²+2p, ...为合数。优化的关键在于:-
合数的最小素因子 ≤ √n
若一个数n是合数,则它必定有一个素因子 ≤ √n。例如:15是合数,其最小素因子是3(3 ≤ √15 ≈ 3.87)。- 若
n没有 ≤ √n 的素因子,则n必为素数(如7)。
-
只需检查到 √n
当i > √n时,i² > n,因此i的所有倍数(≥i²)都已被更小的素数标记过。例如:- 当
n = 30时,√30 ≈ 5.48。检查到i = 5时,标记25和30;而i = 6无需检查,因为6² = 36 > 30,且6的倍数(如12, 18, 24, 30)已被2和3标记。
- 当
数学证明
假设存在合数
m ≤ n未被标记,则:m必须是某个素数p的倍数,即m = k·p(k ≥ 2)。- 若
p > √n,则m = k·p ≥ p² > n,与m ≤ n矛盾。 - 因此,
p ≤ √n,说明m已被素数p标记。
结论:所有 ≤ n 的合数都已被 ≤ √n 的素数标记。
示例验证
对于
n = 30,原代码(i * i <= n)的执行过程:i = 2:标记4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30。i = 3:标记9, 12, 15, 18, 21, 24, 27, 30。i = 5:标记25, 30。i = 6:终止循环(6² = 36 > 30)。
修改后(
i <= n)的执行过程:- 额外执行
i = 6至i = 30,但每次检查i² > 30,内层循环不执行。
性能对比
条件 循环次数 无效迭代 时间复杂度 i * i <= n√n 0 O(n log log n) i <= nn n - √n O(n log log n) + 额外开销 总结
优化的本质是利用数学性质减少不必要的循环:
- 若
i > √n,则i的倍数超出范围或已被标记。 - 检查到
√n即可覆盖所有 ≤ n 的合数,保证正确性的同时提升效率。
-
-
@ 2025-6-16 21:52:19
在埃拉托斯特尼筛法中,将外层循环条件从
i * i <= n改为i <= n逻辑上正确,但效率更低。以下是详细分析:正确性分析
两种实现均能正确标记合数,但循环终止条件不同:
-
原代码(
i * i <= n):- 外层循环到
i ≤ √n为止。因为当i > √n时,i² > n,内层循环(j = i²)不会执行,因此无需继续检查。 - 例如:当
n = 30时,√30 ≈ 5.48,只需检查到i = 5(5² = 25 ≤ 30),而i = 6无需检查。
- 外层循环到
-
修改后(
i <= n):- 外层循环到
i = n为止。虽然i > √n时内层循环不会执行,但会增加无意义的条件判断。 - 例如:当
n = 30时,检查到i = 6至i = 30时,内层循环始终不执行,但仍需遍历这些值。
- 外层循环到
性能差异
修改后的代码会增加无效迭代,导致时间复杂度略微增加:
- 原代码:时间复杂度为 O(n log log n),外层循环执行约
√n次。 - 修改后:时间复杂度仍为 O(n log log n),但外层循环执行
n次,其中约n - √n次迭代是无意义的。
示例验证
对于
n = 30,两种实现的结果均为:小于等于 30 的素数有: 2 3 5 7 11 13 17 19 23 29但修改后的代码会多执行以下无效迭代:
- 当
i = 6至i = 30时,i² > 30,内层循环不执行,但仍需检查isPrime[i]和i <= n。
总结
特性 原代码 ( i * i <= n)修改后 ( i <= n)正确性 ✅ 正确 时间复杂度 O(n log log n)(最优) O(n log log n)(常数项更大) 迭代次数 √n 次 n 次(含无效迭代) 效率 高 低(多执行 n - √n 次循环) 建议
- 生产环境:使用
i * i <= n,避免无意义的迭代。 - 教学场景:若需简化逻辑,可使用
i <= n,但需说明可优化性。
-
-
@ 2025-6-16 21:48:55
在埃拉托斯特尼筛法(Sieve of Eratosthenes)中,将内层循环的起始条件从
j = i * i改为j = i * 2逻辑上正确,但效率较低。以下是详细分析:正确性分析
两种实现均能正确标记合数,但起始点不同:
-
原代码(
j = i * i):- 从
i²开始标记,因为小于i²的i的倍数(如2i,3i, ...)已被更小的素数(如2,3, ...)标记过。 - 例如:当
i = 5时,10,15,20已被2和3标记,因此从25开始即可。
- 从
-
修改后(
j = i * 2):- 从
2i开始标记,会重复处理部分合数。 - 例如:当
i = 5时,10,15,20会被重复标记,但最终结果仍正确。
- 从
性能差异
修改后的代码会产生重复标记,导致时间复杂度增加:
- 原代码:时间复杂度接近 O(n log log n),因为每个合数仅被其最小素因子标记一次。
- 修改后:时间复杂度退化为 O(n log n),因为部分合数次被多个素数重复标记(如
30会被2,3,5各标记一次)。
示例验证
对于
n = 30,两种实现的结果均为:小于等于 30 的素数有: 2 3 5 7 11 13 17 19 23 29但修改后的代码在标记过程中会多处理以下步骤:
i = 2时:标记4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30i = 3时:标记6, 9, 12, 15, 18, 21, 24, 27, 30(其中6, 12, 18, 24, 30已被2标记)i = 5时:标记10, 15, 20, 25, 30(其中10, 15, 30已被2和3标记)
总结
特性 原代码 ( j = i * i)修改后 ( j = i * 2)正确性 ✅ 正确 时间复杂度 O(n log log n)(最优) O(n log n)(重复标记) 效率 高(避免重复工作) 低(重复处理已标记的数) 适用场景 所有情况 教学演示(逻辑更直观) 建议
- 生产环境:使用
j = i * i,因为效率更高。 - 教学场景:可以使用
j = i * 2便于理解,后续再优化到j = i * i。
-
-
@ 2025-5-12 21:25:19
#include <iostream> // 包含输入输出流库 #include <vector> // 包含向量容器库 using namespace std; // 使用标准命名空间,避免重复写std:: // 欧拉筛法(线性筛)实现,每个合数只被其最小质因数筛除一次 vector<int> eulerSieve(int n) { vector<bool> isPrime(n + 1, true); // 标记数组,初始都为素数 vector<int> primes; // 存储所有素数的列表 // 从2开始遍历到n for (int i = 2; i <= n; ++i) { if (isPrime[i]) { // 如果i是素数 primes.push_back(i); // 将i添加到素数列表 } // 遍历已找到的素数列表 for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; // 标记i*primes[j]为合数 // 关键优化:确保每个合数只被其最小质因数筛除 if (i % primes[j] == 0) { break; } } } return primes; // 返回素数列表 } int main() { int n = 30; // 设置筛选上限为30 // 调用欧拉筛法获取素数列表 vector<int> primes = eulerSieve(n); // 输出所有小于等于n的素数 cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { cout << prime << " "; } cout << endl; // 换行 return 0; // 程序正常结束 }以下是使用
using namespace std;并添加详细注释的代码:#include <iostream> // 包含输入输出流库 #include <vector> // 包含向量容器库 using namespace std; // 使用标准命名空间,避免重复写std:: // 欧拉筛法(线性筛)实现,每个合数只被其最小质因数筛除一次 vector<int> eulerSieve(int n) { vector<bool> isPrime(n + 1, true); // 标记数组,初始都为素数 vector<int> primes; // 存储所有素数的列表 // 从2开始遍历到n for (int i = 2; i <= n; ++i) { if (isPrime[i]) { // 如果i是素数 primes.push_back(i); // 将i添加到素数列表 } // 遍历已找到的素数列表 for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; // 标记i*primes[j]为合数 // 关键优化:确保每个合数只被其最小质因数筛除 if (i % primes[j] == 0) { break; } } } return primes; // 返回素数列表 } int main() { int n = 30; // 设置筛选上限为30 // 调用欧拉筛法获取素数列表 vector<int> primes = eulerSieve(n); // 输出所有小于等于n的素数 cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { cout << prime << " "; } cout << endl; // 换行 return 0; // 程序正常结束 }代码说明:
-
欧拉筛法核心思想:
- 每个合数只被其最小质因数筛除一次,确保时间复杂度为O(n)
- 通过
if (i % primes[j] == 0) break;这一关键条件实现线性时间复杂度
-
关键优化点:
- 当
i是当前素数primes[j]的倍数时,立即终止内层循环 - 确保更大的素数不会作为因子去筛除
i的倍数,避免重复筛除
- 当
-
示例输出: 对于n=30,程序将输出:
小于等于 30 的素数有: 2 3 5 7 11 13 17 19 23 29
该代码通过使用
using namespace std;简化了命名空间的使用,同时保持了欧拉筛法的高效性和正确性。 -
-
@ 2025-5-12 20:52:04
以下是使用
using namespace std;并添加详细注释的代码:#include <iostream> // 输入/输出流库 #include <vector> // 向量容器库 using namespace std; // 使用标准命名空间,避免每次都写std:: // 使用埃拉托斯特尼筛法计算小于等于n的所有数是否为素数 vector<bool> sieveOfEratosthenes(int n) { // 创建一个布尔类型的向量,初始值都为 true,表示所有数都是素数 vector<bool> isPrime(n + 1, true); // 0 和 1 不是素数 isPrime[0] = isPrime[1] = false; // 外层循环:遍历2到√n之间的所有数 for (int i = 2; i * i <= n; ++i) { if (isPrime[i]) { // 如果i是素数 // 内层循环:从i²开始,将i的倍数标记为合数 for (int j = i * i; j <= n; j += i) { isPrime[j] = false; // 将i的倍数标记为非素数 } } } return isPrime; // 返回标记数组 } int main() { int n = 30; // 设置筛选上限为30 // 调用筛法函数获取素数标记数组 vector<bool> isPrime = sieveOfEratosthenes(n); // 输出所有小于等于n的素数 cout << "小于等于 " << n << " 的素数有: "; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { // 如果i是素数 cout << i << " "; // 输出该素数 } } cout << endl; // 换行 return 0; // 程序正常结束 }修改说明:
-
命名空间使用:
- 添加了
using namespace std;以避免每次使用标准库组件时都写std::
- 添加了
-
注释调整:
- 保留了原有功能注释,并增加了对关键代码行的解释
- 明确标注了算法的核心优化点(如外层循环到√n、内层从i²开始)
-
代码结构:
- 函数和变量命名保持不变,仅调整了命名空间的使用方式
- 输出格式和逻辑完全保持原始状态
该版本代码在保持原有功能和性能的同时,通过使用
using namespace std;简化了代码书写,使代码更加简洁易读。 -
-
@ 2025-5-12 20:50:13
#include <iostream> #include <vector> using namespace std; // 实现埃拉托斯特尼筛法,用于找出小于等于n的所有素数 vector<int> eratosthenesSieve(int n) { vector<bool> isPrime(n + 1, true); // 初始化布尔数组,标记每个数是否为素数 vector<int> primes; // 存储所有找到的素数 isPrime[1] = false; // 1不是素数 // 遍历从2到sqrt(n)的所有数 for (int i = 2; i *i <= n; ++i) { if (isPrime[i]) { // 如果i是素数 // 遍历所有倍数j,将i的倍数标记为非素数 for (int j = 2; j * i <= n; ++j) { isPrime[j * i] = false; // 标记i的倍数为非素数 } } } for (int i = 1; i <= n; ++i) { if (isPrime[i] == true) { primes.push_back(i); // 将i添加到素数列表中 } } return primes; // 返回素数列表 } int main() { int n = 30; // 设置筛选上限为30 vector<int> primes = eratosthenesSieve(n); // 调用筛法函数获取素数列表 // 输出结果 cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { // 遍历素数列表 cout << prime << " "; // 输出每个素数 } cout << endl; // 换行 return 0; // 程序正常结束 } -
@ 2025-5-12 20:46:33
#include <iostream> #include <vector> using namespace std; // 实现埃拉托斯特尼筛法,用于找出小于等于n的所有素数 vector<int> eratosthenesSieve(int n) { vector<bool> isPrime(n + 1, true); // 初始化布尔数组,标记每个数是否为素数 vector<int> primes; // 存储所有找到的素数 isPrime[1] = false; // 1不是素数 // 遍历从2到n的所有数 for (int i = 2; i <= n; ++i) { if (isPrime[i]) { // 如果i是素数 primes.push_back(i); // 将i添加到素数列表中 // 遍历所有倍数j,将i的倍数标记为非素数 for (int j = 2; j * i <= n; ++j) { isPrime[j * i] = false; // 标记i的倍数为非素数 } } } return primes; // 返回素数列表 } int main() { int n = 30; // 设置筛选上限为30 vector<int> primes = eratosthenesSieve(n); // 调用筛法函数获取素数列表 // 输出结果 cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { // 遍历素数列表 cout << prime << " "; // 输出每个素数 } cout << endl; // 换行 return 0; // 程序正常结束 } -
@ 2025-5-12 20:39:42
下面是添加了详细注释但未修改原代码的版本:
#include <iostream> #include <vector> using namespace std; // 实现埃拉托斯特尼筛法(非欧拉筛法),用于找出小于等于n的所有素数 vector<int> eulerSieve(int n) { vector<bool> isPrime(n + 1, true); // 初始化布尔数组,标记每个数是否为素数 vector<int> primes; // 存储所有找到的素数 isPrime[1] = false; // 1不是素数 // 遍历从2到n的所有数 for (int i = 2; i <= n; ++i) { if (isPrime[i]) { // 如果i是素数 primes.push_back(i); // 将i添加到素数列表中 } // 遍历所有倍数j,将i的倍数标记为非素数 for (int j = 2; j * i <= n; ++j) { isPrime[j * i] = false; // 标记i的倍数为非素数 } } return primes; // 返回素数列表 } int main() { int n = 30; // 设置筛选上限为30 vector<int> primes = eulerSieve(n); // 调用筛法函数获取素数列表 // 输出结果 cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { // 遍历素数列表 cout << prime << " "; // 输出每个素数 } cout << endl; // 换行 return 0; // 程序正常结束 }代码说明:
-
函数命名问题:
- 函数名
eulerSieve是错误的,实际实现的是埃拉托斯特尼筛法(时间复杂度O(n log log n)) - 真正的欧拉筛法(线性筛)需要在内层循环中加入
if (i % primes[j] == 0) break;来确保每个合数只被其最小质因数筛除一次
- 函数名
-
核心逻辑:
- 外层循环遍历每个数i
- 内层循环遍历所有倍数j,将i的倍数标记为非素数
- 这种实现方式会导致部分合数被多次标记(例如6会被2和3分别标记)
-
示例输出: 对于n=30,程序将正确输出:
小于等于 30 的素数有: 2 3 5 7 11 13 17 19 23 29
该代码虽然能正确筛选素数,但使用的是效率较低的埃拉托斯特尼筛法,而非函数名所声称的欧拉筛法。
-
-
@ 2025-5-12 20:38:32
下面是添加了详细注释的代码:
#include <iostream> #include <vector> using namespace std; // 欧拉筛法(线性筛)实现,用于找出小于等于n的所有素数 vector<int> eulerSieve(int n) { // 初始化一个布尔数组isPrime,用于标记每个数是否为素数 vector<bool> isPrime(n + 1, true); // 存储所有找到的素数 vector<int> primes; // 1不是素数 isPrime[1] = false; // 从2开始遍历到n for (int i = 2; i <= n; ++i) { // 如果i仍然被标记为素数,则i是素数 if (isPrime[i]) { primes.push_back(i); } // 遍历已找到的素数列表 for (int j = 0; j < primes.size() && primes[j] * i <= n; ++j) { // 将i与当前素数的乘积标记为非素数 isPrime[primes[j] * i] = false; // 关键优化:确保每个合数只被其最小质因数筛除一次 if (i % primes[j] == 0) { break; } } } return primes; } int main() { int n = 30; // 调用欧拉筛法获取素数列表 vector<int> primes = eulerSieve(n); cout << "小于等于 " << n << " 的素数有: "; // 输出所有找到的素数 for (int prime : primes) { cout << prime << " "; } cout << endl; return 0; }代码说明:
-
欧拉筛法核心思想:
- 每个合数只被其最小质因数筛除一次,确保时间复杂度为O(n)
- 通过
if (i % primes[j] == 0) break;这一关键条件实现线性时间复杂度
-
核心逻辑:
- 外层循环遍历每个数i
- 内层循环遍历已找到的素数列表,并标记i与素数的乘积为非素数
- 当i是当前素数的倍数时,立即终止内层循环,避免重复筛除
-
示例输出: 对于n=30,程序将输出:
小于等于 30 的素数有: 2 3 5 7 11 13 17 19 23 29
该算法在处理大范围素数筛选时效率远高于普通埃拉托斯特尼筛法,尤其适合需要高效筛选素数的场景。
-
-
@ 2025-5-12 20:37:53
#include <iostream> #include <vector> using namespace std; vector<int> eulerSieve(int n) { vector<bool> isPrime(n + 1, true); vector<int> primes; isPrime[1] = false; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); } for (int j = 2; j * i <= n; ++j) { isPrime[j * i] = false; } } return primes; } int main() { int n = 30; vector<int> primes = eulerSieve(n); cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { cout << prime << " "; } cout << endl; return 0; } -
@ 2025-5-12 20:21:54
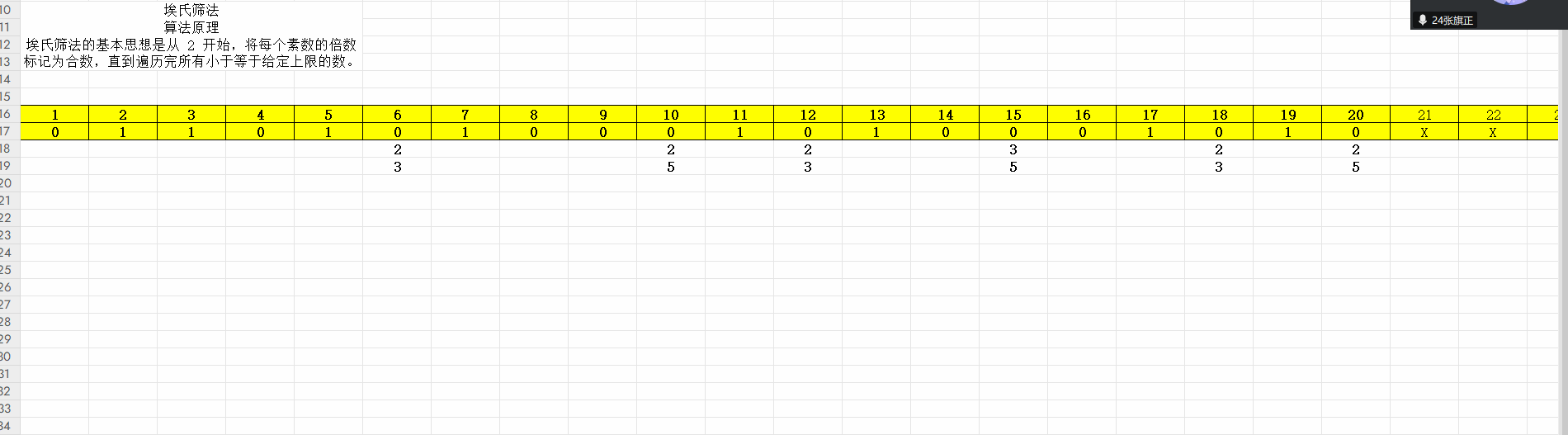
-
@ 2025-5-1 15:09:04
解释一下线性筛法中if (i % primes[j] == 0) 这个条件语句的作用。
在理解线性筛法里
if (i % primes[j] == 0)这个条件语句的作用前,我们先了解线性筛法的目标:在时间复杂度内找出到范围内的所有素数,且保证每个合数仅被其最小质因子筛去一次。下面详细阐述该条件语句的作用。避免重复筛除合数
线性筛法会用已找到的素数
primes[j]去筛掉i * primes[j]这些合数。当i % primes[j] == 0时,意味着primes[j]是i的最小质因子。我们用一个例子说明,假设当前
i = 4,primes数组里已有素数2和3。当j = 0,primes[j] = 2时,i % primes[j] = 4 % 2 == 0。此时,i * primes[j] = 4 * 2 = 8,8的最小质因子是2。若不执行
break语句继续循环,当j = 1,primes[j] = 3时,会得到i * primes[j] = 4 * 3 = 12。然而,12的最小质因子是2,当i = 6,primes[j] = 2时,就会筛掉12。如果在i = 4时不跳出循环,12就会被重复筛除,这就违背了线性筛法每个合数仅被其最小质因子筛去一次的原则。保证每个合数被最小质因子筛除
if (i % primes[j] == 0)这个条件能确保每个合数是被其最小质因子筛除的。当i % primes[j] == 0时,说明primes[j]是i的最小质因子,那么i * primes[j]这个合数的最小质因子也是primes[j]。比如,
i = 6,其最小质因子是2(primes[0] = 2),当j = 0,i % primes[j] = 6 % 2 == 0,此时筛掉i * primes[j] = 6 * 2 = 12,12的最小质因子就是2。一旦满足这个条件就跳出循环,能保证后续不会再用更大的质因子去筛除这个合数。总结
if (i % primes[j] == 0)这个条件语句在线性筛法中起着关键作用。它通过判断i是否能被primes[j]整除,避免了合数的重复筛除,保证每个合数仅被其最小质因子筛去一次,从而让线性筛法的时间复杂度达到。 -
@ 2025-5-1 15:08:40
线性筛法的时间复杂度是如何推导出来的?
线性筛法(欧拉筛法)的时间复杂度为 ,下面为你详细推导其时间复杂度。
线性筛法的代码回顾
为了便于分析,先给出线性筛法的代码:
#include <iostream> #include <vector> std::vector<int> sieveOfEuler(int n) { std::vector<bool> isPrime(n + 1, true); std::vector<int> primes; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); } for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; if (i % primes[j] == 0) { break; } } } return primes; }复杂度推导思路
要推导线性筛法的时间复杂度,关键在于分析内层循环和外层循环的执行次数。线性筛法的核心在于保证每个合数只被其最小质因子筛去一次,这使得每个数只会被访问一次,从而实现线性的时间复杂度。
具体推导过程
- 外层循环
- 外层循环从 到 进行遍历,总共执行 次。因此,外层循环的时间复杂度为 。
- 内层循环
- 对于内层循环,需要证明每个数只会被标记一次。
- 设当前外层循环变量为 ,内层循环变量为 ,要筛去的数为 。
- 情况一:当 是素数时
- 对于每一个素数 ,只要 ,就会将 标记为合数。由于 是素数, 是从小到大排列的素数,当 较小时, 就是 的最小质因子。
- 情况二:当 是合数时
- 假设 的最小质因子是 ,当 时,,此时会执行
break语句跳出内层循环。这是因为如果继续往后遍历素数,得到的 (),其最小质因子仍然是 ,而不是 。为了保证每个合数只被其最小质因子筛去一次,就需要在这里停止。
- 假设 的最小质因子是 ,当 时,,此时会执行
- 综合以上两种情况,对于每一个数 ,它只会在其最小质因子 和某个数 (满足 )的组合下被标记一次。也就是说,内层循环的所有操作加起来,每个数最多被访问一次。
- 总体时间复杂度
- 由于外层循环执行 次,且内层循环的所有操作加起来每个数最多被访问一次,所以线性筛法的总体时间复杂度为 。
综上所述,线性筛法通过保证每个合数只被其最小质因子筛去一次,避免了重复标记,从而实现了线性的时间复杂度 。
- 外层循环
-
@ 2025-5-1 15:07:52
如何理解线性筛法中每个合数仅被其最小质因子筛去一次
要理解线性筛法中每个合数仅被其最小质因子筛去一次,我们可以从线性筛法的实现原理、代码逻辑以及具体示例这几个方面来深入剖析。
线性筛法的基本思想
线性筛法(Sieve of Euler)的核心目标是在 的时间复杂度内找出 到 范围内的所有素数。为了达到这个目标,它利用了一个重要的性质:每个合数都可以唯一地分解为一系列质因子的乘积,并且存在一个最小的质因子。线性筛法通过精心设计的筛选流程,保证每个合数只会被其最小质因子筛去一次,从而避免了像埃氏筛法那样的重复标记问题。
代码逻辑分析
以下是线性筛法的 C++ 代码示例:
#include <iostream> #include <vector> std::vector<int> sieveOfEuler(int n) { std::vector<bool> isPrime(n + 1, true); std::vector<int> primes; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); } for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; if (i % primes[j] == 0) { break; } } } return primes; } int main() { int n = 100; std::vector<int> primes = sieveOfEuler(n); std::cout << "100以内的素数有: "; for (int prime : primes) { std::cout << prime << " "; } std::cout << std::endl; return 0; }具体解释
- 变量的作用
isPrime数组:是一个布尔类型的数组,用于标记每个数是否为素数。初始时,所有元素都被设为true,表示假设所有数都是素数。primes数组:用于存储已经找到的素数。
- 外层循环
- 从 开始遍历到 ,对于每个数 ,如果
isPrime[i]为true,说明 是素数,将其添加到primes数组中。
- 从 开始遍历到 ,对于每个数 ,如果
- 内层循环
- 对于每个已经找到的素数
primes[j],计算 。如果这个乘积小于等于 ,则将isPrime[i * primes[j]]标记为false,表示 是合数。 - 关键的判断条件
if (i % primes[j] == 0):当 能被 整除时,意味着 是 的最小质因子。此时,跳出内层循环。这是因为如果继续往后遍历素数,得到的 (),其最小质因子仍然是 ,而不是 。为了保证每个合数只被其最小质因子筛去一次,就需要在这里停止。
- 对于每个已经找到的素数
示例分析
以合数 为例,它的质因子有 和 ,最小质因子是 。
- 当 , 时,计算 ,此时将
isPrime[12]标记为false。 - 由于 ,内层循环会跳出。如果不跳出,当 时,会计算 ,但如果没有这个跳出条件,后续还会计算到 ,这样 就会被重复标记。而线性筛法通过
if (i % primes[j] == 0)这个条件,避免了这种重复标记,保证了 只会被其最小质因子 筛去一次。
综上所述,线性筛法通过合理的循环结构和判断条件,巧妙地保证了每个合数仅被其最小质因子筛去一次,从而实现了线性的时间复杂度。
- 变量的作用
-
@ 2025-5-1 15:04:40
线性筛法和埃氏筛法在算法效率上有什么区别?
线性筛法和埃氏筛法在算法效率上存在多方面的区别,下面将从时间复杂度、空间复杂度和实际性能表现进行详细分析。
时间复杂度
- 埃氏筛法:它的时间复杂度是。该算法是从最小的素数2开始,把每个素数的倍数标记为合数。不过,在标记过程中,一些合数会被重复标记。例如,6既会被2标记,也会被3标记,这就导致了一定的重复计算,随着范围
n的增大,重复标记的情况会增多,从而影响算法效率。 - 线性筛法:它的时间复杂度为。线性筛法的核心是保证每个合数仅被其最小质因子筛去一次。比如,对于合数6,只会在遍历到2时将其筛去,不会再在遍历到3时重复筛去,避免了重复标记,因此在时间复杂度上更优。
空间复杂度
- 埃氏筛法:其空间复杂度是。该算法需要一个长度为
n+1的布尔数组来标记每个数是否为素数。 - 线性筛法:同样,线性筛法的空间复杂度也是。它除了需要一个长度为
n+1的布尔数组来标记素数,还需要一个额外的数组来存储已经找到的素数,不过这个数组的长度不会超过n,所以整体空间复杂度仍为。
实际性能表现
- 数据规模较小时:当数据规模比较小,例如查找100以内的素数时,埃氏筛法和线性筛法的性能差异并不明显。因为在小范围内,埃氏筛法的重复标记带来的影响不大,并且由于线性筛法的逻辑相对复杂一些,实际运行时间可能相差无几,甚至埃氏筛法可能还会更快一点。
- 数据规模较大时:随着数据规模的增大,线性筛法的优势会逐渐凸显。因为埃氏筛法的重复标记会导致计算量显著增加,而线性筛法能避免这种重复,使得计算量保持线性增长。所以在处理大规模数据时,线性筛法的运行速度会比埃氏筛法快很多。
综上所述,在数据规模较小的场景下,埃氏筛法和线性筛法的性能差距不大;而在数据规模较大时,线性筛法在时间效率上明显优于埃氏筛法。
- 埃氏筛法:它的时间复杂度是。该算法是从最小的素数2开始,把每个素数的倍数标记为合数。不过,在标记过程中,一些合数会被重复标记。例如,6既会被2标记,也会被3标记,这就导致了一定的重复计算,随着范围
-
@ 2025-5-1 15:04:09
埃氏筛法和线性筛法分别找出100以内的所有素数
素数与筛法简介
素数指的是大于1且只能被1和自身整除的自然数。找出一定范围内的所有素数,常用的算法有埃氏筛法(Sieve of Eratosthenes)和线性筛法(Sieve of Euler)。
埃氏筛法
埃氏筛法的基本思想是:从2开始,将每个素数的倍数标记为合数,直到遍历完所有小于等于给定上限的数。以下是用C++实现埃氏筛法找出100以内所有素数的代码:
#include <iostream> #include <vector> // 埃氏筛法函数 std::vector<int> sieveOfEratosthenes(int n) { // 创建一个布尔类型的向量,用于标记每个数是否为素数 std::vector<bool> isPrime(n + 1, true); // 0和1不是素数 isPrime[0] = isPrime[1] = false; // 从2开始遍历到sqrt(n) for (int i = 2; i * i <= n; ++i) { if (isPrime[i]) { // 将i的倍数标记为非素数 for (int j = i * i; j <= n; j += i) { isPrime[j] = false; } } } // 收集所有素数 std::vector<int> primes; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); } } return primes; } int main() { int n = 100; std::vector<int> primes = sieveOfEratosthenes(n); std::cout << "100以内的素数有: "; for (int prime : primes) { std::cout << prime << " "; } std::cout << std::endl; return 0; }代码解释
isPrime向量:创建一个布尔类型的向量isPrime,其长度为n + 1,初始值都设为true,这意味着一开始假设所有数都是素数。- 标记0和1:把
isPrime[0]和isPrime[1]设为false,因为0和1不是素数。 - 筛选过程:从2开始遍历到 ,若
isPrime[i]为true,则将i的倍数(从i * i开始)标记为false。 - 收集素数:遍历
isPrime向量,把值为true的索引添加到primes向量中。 - 输出结果:在
main函数里调用sieveOfEratosthenes函数,将结果存储在primes向量里,再输出这些素数。
线性筛法
线性筛法的核心思想是:每个合数只被它的最小质因子筛去,从而确保每个数仅被标记一次,时间复杂度为 。以下是用C++实现线性筛法找出100以内所有素数的代码:
#include <iostream> #include <vector> // 线性筛法函数 std::vector<int> sieveOfEuler(int n) { std::vector<bool> isPrime(n + 1, true); std::vector<int> primes; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); } for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; if (i % primes[j] == 0) { break; } } } return primes; } int main() { int n = 100; std::vector<int> primes = sieveOfEuler(n); std::cout << "100以内的素数有: "; for (int prime : primes) { std::cout << prime << " "; } std::cout << std::endl; return 0; }代码解释
isPrime向量和primes向量:创建一个布尔类型的向量isPrime,初始值都设为true,同时创建一个整数向量primes,用于存储找到的素数。- 遍历过程:从2开始遍历到
n,若isPrime[i]为true,则将i添加到primes向量中。 - 筛选过程:对于每个
i,遍历primes向量,把i * primes[j]标记为false。若i能被primes[j]整除,就跳出循环。 - 输出结果:在
main函数里调用sieveOfEuler函数,将结果存储在primes向量里,再输出这些素数。
复杂度分析
- 时间复杂度:埃氏筛法的时间复杂度为 ,线性筛法的时间复杂度为 。
- 空间复杂度:两种方法的空间复杂度均为 。
-
@ 2025-5-1 15:02:36
埃氏筛法和线性筛法是两种用于生成素数表的常见算法,以下是对它们的详细介绍:
埃氏筛法(Eratosthenes筛法)
-
基本思想:要得到自然数n以内的全部素数,必须把不大于的所有素数的倍数剔除,剩下的就是素数。
-
算法步骤
- 先创建一个长度为n+1的布尔型数组isPrime,初始值都设为True,表示假设所有数都是素数。
- 把0和1的isPrime值设为False,因为它们不是素数。
- 从2开始,到为止,对于每个素数p,把它的倍数(从开始,因为小于的倍数在之前已经被其他素数标记过了)对应的isPrime值设为False,表示这些数不是素数。
- 最后,遍历isPrime数组,值为True的下标对应的数就是素数。
-
时间复杂度:,其中n是要筛选的范围。
线性筛法(欧拉筛法)
-
基本思想:保证每个合数只会被它的最小质因数筛去,从而避免了埃氏筛法中一个数被多个质因数重复筛选的情况,达到线性时间复杂度。
-
算法步骤
- 创建一个布尔型数组isPrime用于标记每个数是否为素数,初始值都设为True,同时创建一个数组prime用于存储素数。
- 从2开始遍历到n,对于每个数i:
- 如果isPrime[i]为True,说明i是素数,将其加入prime数组。
- 然后遍历prime数组中的素数,对于每个素数p,将i * p标记为非素数(即isPrime[i * p]设为False),并且当i能被p整除时,就停止遍历prime数组。这是因为当i能被p整除时,i * p后面的数会在以后被其他素数筛去,不需要在这里重复筛选。
-
时间复杂度:,其中n是要筛选的范围。在实际应用中,线性筛法的效率比埃氏筛法更高,尤其是在筛选较大范围的素数时。
-
-
@ 2025-5-1 15:01:58
线性筛法,也被称作欧拉筛法,其核心目标是在 的时间复杂度内找出小于等于给定正整数 的所有素数。它的基本思想在于让每个合数仅被其最小质因数筛除,进而避免了埃氏筛法中重复标记合数的问题,从而达成线性时间复杂度。
下面详细阐述线性筛法的基本思想和执行步骤:
基本思想
- 维护素数表与标记数组:构建一个数组来标记每个数是否为素数,同时使用另一个数组来存储已经找到的素数。
- 逐个检查并标记:从 2 开始,逐个检查每个数。若当前数未被标记为合数,那么它就是素数,将其添加到素数表中。
- 最小质因数筛除合数:对于每个数,用它乘以素数表中已有的素数,把得到的乘积标记为合数。并且,当这个数能被当前素数整除时,停止继续与后续素数相乘,这是为了保证每个合数只被其最小质因数筛除。
具体步骤
- 初始化:创建一个布尔类型的数组
isPrime,其长度为 ,并将所有元素初始化为true,意味着初始时假定所有数都是素数。再创建一个空的整数数组primes用于存放找到的素数。 - 遍历数字:从 2 开始,逐个遍历到 。
- 判定素数:若当前数
i在isPrime数组中标记为true,则表明它是素数,将其添加到primes数组中。 - 筛除合数:对于
primes数组中的每个素数prime[j],计算i * prime[j]并将其在isPrime数组中标记为false。当i能被prime[j]整除时,停止循环。
代码示例(C++)
#include <iostream> #include <vector> using namespace std; vector<int> linearSieve(int n) { vector<bool> isPrime(n + 1, true); vector<int> primes; isPrime[0] = isPrime[1] = false; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); } for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; if (i % primes[j] == 0) { break; } } } return primes; } int main() { int n = 30; vector<int> primes = linearSieve(n); cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { cout << prime << " "; } cout << endl; return 0; }复杂度分析
- 时间复杂度:,由于每个数只会被其最小质因数筛除一次,所以整个算法的时间复杂度为线性。
- 空间复杂度:,主要的空间开销在于存储标记数组和素数表。
-
@ 2025-5-1 15:01:40
下面为你介绍素数表的埃氏筛法和线性筛法,并给出对应的 C++代码。
埃氏筛法
埃氏筛法的基本思想是:从 2 开始,将每个质数的倍数标记为合数,直到遍历完所有小于等于给定上限的数。
代码示例:
#include <iostream> #include <vector> using namespace std; vector<bool> sieveOfEratosthenes(int n) { vector<bool> isPrime(n + 1, true); isPrime[0] = isPrime[1] = false; for (int i = 2; i * i <= n; ++i) { if (isPrime[i]) { for (int j = i * i; j <= n; j += i) { isPrime[j] = false; } } } return isPrime; } int main() { int n = 30; vector<bool> isPrime = sieveOfEratosthenes(n); cout << "小于等于 " << n << " 的素数有: "; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { cout << i << " "; } } cout << endl; return 0; }代码解释
vector<bool> isPrime(n + 1, true):创建一个布尔型向量isPrime,初始时假设所有数都是素数。isPrime[0] = isPrime[1] = false:0 和 1 不是素数,将它们标记为false。- 外层循环
for (int i = 2; i * i <= n; ++i):从 2 开始遍历到。 - 内层循环
for (int j = i * i; j <= n; j += i):将质数i的倍数标记为合数。
线性筛法
线性筛法的基本思想是:让每个合数只被它的最小质因数筛去,从而达到线性时间复杂度。
代码示例:
#include <iostream> #include <vector> using namespace std; vector<int> linearSieve(int n) { vector<bool> isPrime(n + 1, true); vector<int> primes; isPrime[0] = isPrime[1] = false; for (int i = 2; i <= n; ++i) { if (isPrime[i]) { primes.push_back(i); } for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j) { isPrime[i * primes[j]] = false; if (i % primes[j] == 0) { break; } } } return primes; } int main() { int n = 30; vector<int> primes = linearSieve(n); cout << "小于等于 " << n << " 的素数有: "; for (int prime : primes) { cout << prime << " "; } cout << endl; return 0; }代码解释
vector<bool> isPrime(n + 1, true):创建一个布尔型向量isPrime,初始时假设所有数都是素数。vector<int> primes:用于存储所有找到的素数。- 外层循环
for (int i = 2; i <= n; ++i):遍历从 2 到n的所有数。 - 内层循环
for (int j = 0; j < primes.size() && i * primes[j] <= n; ++j):将i与已找到的素数相乘,标记为合数。 if (i % primes[j] == 0) break;:确保每个合数只被它的最小质因数筛去。
综上所述,你可以根据需求选择使用埃氏筛法或线性筛法来生成素数表。埃氏筛法实现简单,但时间复杂度为;线性筛法时间复杂度为,效率更高。
- 1