以下是一个简单易懂的 C++ 线段树教程,用生活化的比喻和分步解释,帮你快速掌握核心思想:
🌳 线段树:像切蛋糕一样处理区间问题
一、什么是线段树?
想象你要管理一家奶茶店的订单,需要快速回答这些问题:
- "下午2点到5点卖了多少杯?"(区间求和)
- "今天销量最高的是哪一小时?"(区间最大值)
如果用普通方法计算,每次都要遍历所有数据,效率低。线段树就像把时间轴切分成多个小段,预先记录每个时间段的信息,查询时直接拼装结果。
二、线段树的本质
把数组像切蛋糕一样不断二分,直到每个小块不能再分割。例如数组 [1,3,5,7] 的切分过程:
[0-3](总和16)
/ \
[0-1](4) [2-3](12)
/ \ / \
0(1) 1(3) 2(5) 3(7)
三、手把手实现线段树(区间求和版)
1. 准备工作
const int MAXN = 1e5; // 假设最大数据量
int arr[MAXN]; // 原始数组(建议从0开始存)
int tree[4 * MAXN]; // 线段树数组(需要4倍空间)
2. 建树:搭建信息金字塔(⚡时间复杂度 O(n))
// node: 当前节点编号(像门牌号)
// start/end: 当前节点管理的区间
void build(int node, int start, int end) {
if (start == end) { // 到达叶子节点
tree[node] = arr[start];
return;
}
int mid = (start + end) / 2;
int leftChild = 2 * node + 1; // 左孩子(类似数组堆的存储方式)
int rightChild = 2 * node + 2; // 右孩子
build(leftChild, start, mid); // 建左半子树
build(rightChild, mid + 1, end);// 建右半子树
tree[node] = tree[leftChild] + tree[rightChild]; // 合并子节点结果
}
3. 查询:快速获取区间和(⚡时间复杂度 O(log n))
// [l, r]是查询区间,[start, end]是当前节点的管理区间
int query(int node, int start, int end, int l, int r) {
if (r < start || end < l) // 完全没交集
return 0;
if (l <= start && end <= r) // 完全在查询区间内
return tree[node];
// 部分重叠,继续向下查
int mid = (start + end) / 2;
int leftSum = query(2*node+1, start, mid, l, r);
int rightSum = query(2*node+2, mid+1, end, l, r);
return leftSum + rightSum;
}
4. 更新:修改某个元素的值(⚡时间复杂度 O(log n))
void update(int node, int start, int end, int index, int value) {
if (start == end) { // 找到目标位置
arr[index] = value;
tree[node] = value;
return;
}
int mid = (start + end) / 2;
if (index <= mid) // 要更新的位置在左子树
update(2*node+1, start, mid, index, value);
else // 在右子树
update(2*node+2, mid+1, end, index, value);
tree[node] = tree[2*node+1] + tree[2*node+2]; // 更新父节点
}
四、举个栗子 🌰
int main() {
// 初始化数组 [1,3,5,7](下标0~3)
arr[0] = 1; arr[1] = 3;
arr[2] = 5; arr[3] = 7;
// 建树:根节点是0,管理整个数组[0,3]
build(0, 0, 3);
// 查询区间[1,2]的和:3+5=8
cout << query(0, 0, 3, 1, 2) << endl;
// 更新arr[1]为10
update(0, 0, 3, 1, 10);
// 再次查询[1,2]:10+5=15
cout << query(0, 0, 3, 1, 2) << endl;
return 0;
}
五、重点总结
| 要点 | 说明 |
|---|---|
| 为什么叫线段树 | 每个节点代表一个区间(线段) |
| 为什么需要4倍空间 | 最坏情况需要2^(h+1)个节点,h是树的高度 |
| 索引从0还是1开始 | 都可以,但代码逻辑要一致 |
| 怎么改求最大值 | 把+改成max(),初始化时叶子节点赋值 |
六、常见问题
Q1:为什么查询时判断条件那么复杂?
A1:就像查快递时,包裹可能在左仓库、右仓库,或分散在两个仓库,需要分别查找。
Q2:线段树和前缀数组哪个好?
A2:前缀数组查询快(O(1)),但更新慢(O(n))。线段树适合频繁更新的场景。
Q3:什么时候用线段树?
A3:当需要同时满足 区间查询 和 单点/区间修改 的高效操作时。
通过这个简化版的教程,你已经掌握了线段树的核心思想!下一步可以尝试实现求区间最大值,或者学习进阶技巧——延迟标记(Lazy Propagation)。
8 条评论
-
admin SU @ 2025-2-1 11:37:14

-
@ 2025-2-1 11:35:36

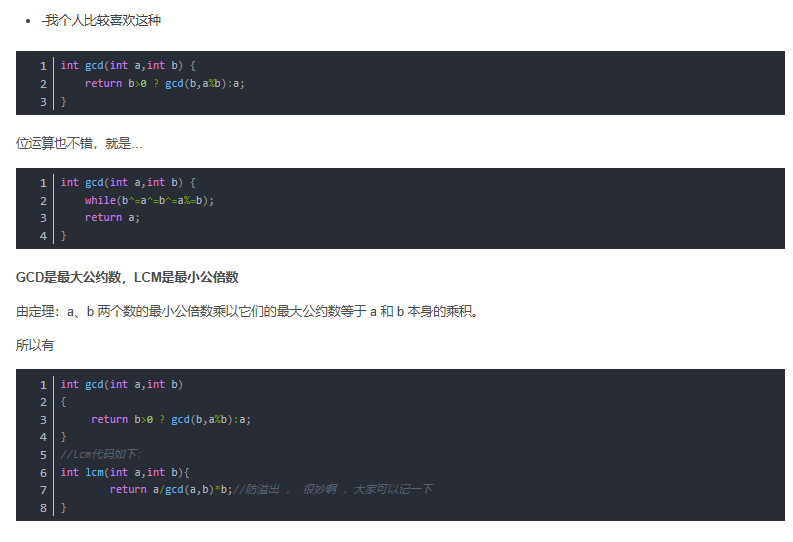
-
@ 2025-2-1 11:34:43
🌟 线段树延迟标记(Lazy Propagation)通俗教程
延迟标记是线段树的一种优化技术,用于高效处理区间更新操作。它的核心思想是:推迟更新,只有在需要时才将更新应用到具体的节点上,从而避免不必要的重复操作。
一、为什么要用延迟标记?
想象你在管理一个图书馆的书架,每次有人借书或还书时,你需要更新书架上的书籍数量。如果每次借还书都更新所有书架,效率会很低。延迟标记就像在书架上贴一张便签:“这些书被借走了”,等到真正需要查询时再更新。
二、延迟标记的核心思想
-
标记(Lazy Tag):
- 每个节点维护一个标记,表示该节点的子节点需要进行的更新操作。
- 标记可以是区间加、区间赋值等。
-
延迟更新:
- 更新时,只更新当前节点,并将更新操作记录在标记中。
- 查询时,如果当前节点有标记,则将标记下传给子节点,并更新子节点的值。
三、手把手实现延迟标记
1. 准备工作
const int MAXN = 1e5; // 假设最大数据量 int arr[MAXN]; // 原始数组 int tree[4 * MAXN]; // 线段树数组 int lazy[4 * MAXN]; // 延迟标记数组2. 建树(Build)
void build(int node, int start, int end) { if (start == end) { // 到达叶子节点 tree[node] = arr[start]; return; } int mid = (start + end) / 2; build(2 * node, start, mid); // 建左子树 build(2 * node + 1, mid + 1, end); // 建右子树 tree[node] = tree[2 * node] + tree[2 * node + 1]; // 合并结果 }3. 标记下传(Push Down)
void pushDown(int node, int start, int end) { if (lazy[node] != 0) { // 如果有标记 int mid = (start + end) / 2; // 更新左子树 tree[2 * node] += lazy[node] * (mid - start + 1); lazy[2 * node] += lazy[node]; // 更新右子树 tree[2 * node + 1] += lazy[node] * (end - mid); lazy[2 * node + 1] += lazy[node]; // 清除当前节点的标记 lazy[node] = 0; } }4. 区间更新(Update)
void update(int node, int start, int end, int l, int r, int val) { if (r < start || end < l) // 完全无交集 return; if (l <= start && end <= r) { // 完全包含 tree[node] += val * (end - start + 1); // 更新当前节点 lazy[node] += val; // 标记延迟更新 return; } pushDown(node, start, end); // 下传标记 int mid = (start + end) / 2; update(2 * node, start, mid, l, r, val); // 更新左子树 update(2 * node + 1, mid + 1, end, l, r, val); // 更新右子树 tree[node] = tree[2 * node] + tree[2 * node + 1]; // 合并结果 }5. 区间查询(Query)
int query(int node, int start, int end, int l, int r) { if (r < start || end < l) // 完全无交集 return 0; if (l <= start && end <= r) // 完全包含 return tree[node]; pushDown(node, start, end); // 下传标记 int mid = (start + end) / 2; int leftSum = query(2 * node, start, mid, l, r); // 查询左子树 int rightSum = query(2 * node + 1, mid + 1, end, l, r); // 查询右子树 return leftSum + rightSum; // 合并结果 }
四、举个栗子 🌰
1. 初始化
int n = 5; arr[1] = 1; arr[2] = 3; arr[3] = 5; arr[4] = 7; arr[5] = 9; build(1, 1, n);2. 区间更新
// 将区间 [2,4] 的所有值加 2 update(1, 1, n, 2, 4, 2);3. 区间查询
// 查询区间 [1,5] 的和 cout << query(1, 1, n, 1, 5) << endl; // 1 + 5 + 7 + 9 + 9 = 31
五、总结
操作 时间复杂度 空间复杂度 建树 O(n) 区间更新 O(log n) O(1) 区间查询
六、常见问题
Q1:为什么需要延迟标记?
A1:延迟标记可以避免不必要的重复更新,将区间更新的时间复杂度优化到O(log n)。Q2:延迟标记适用于哪些操作?
A2:适用于区间加、区间赋值等区间更新操作。Q3:延迟标记的实现难点是什么?
A3:难点在于正确下传标记,确保更新操作不会遗漏或重复。
通过这个通俗易懂的教程,你应该已经掌握了延迟标记的核心思想和实现方法!快去试试解决一些区间更新问题吧!
-
-
@ 2025-2-1 11:17:19
延迟标记(Lazy Propagation)是线段树的一种优化技术,用于高效处理区间更新操作。它的核心思想是:推迟更新,只有在需要时才将更新应用到具体的节点上,从而避免不必要的重复操作。
一、为什么需要延迟标记?
在普通的线段树中,区间更新(如将区间
[L, R]内的所有值加上x)需要递归更新所有相关节点,时间复杂度为O(n)。延迟标记通过延迟更新,将时间复杂度优化到O(log n)。示例
假设需要对区间
[1, 5]的所有值加2:- 普通线段树:递归更新
[1,5]内的所有节点。 - 延迟标记:只在
[1,5]的父节点上标记“需要加2”,等到查询时再实际更新。
二、延迟标记的核心思想
-
标记(Lazy Tag):
- 每个节点维护一个标记,表示该节点的子节点需要进行的更新操作。
- 标记可以是区间加、区间赋值等。
-
延迟更新:
- 更新时,只更新当前节点,并将更新操作记录在标记中。
- 查询时,如果当前节点有标记,则将标记下传给子节点,并更新子节点的值。
三、实现步骤
1. 数据结构
const int MAXN = 1e5; // 假设最大数据量 int arr[MAXN]; // 原始数组 int tree[4 * MAXN]; // 线段树数组 int lazy[4 * MAXN]; // 延迟标记数组2. 初始化
void build(int node, int start, int end) { if (start == end) { tree[node] = arr[start]; return; } int mid = (start + end) / 2; build(2 * node, start, mid); build(2 * node + 1, mid + 1, end); tree[node] = tree[2 * node] + tree[2 * node + 1]; }3. 标记下传(Push Down)
void pushDown(int node, int start, int end) { if (lazy[node] != 0) { // 如果有标记 int mid = (start + end) / 2; // 更新左子树 tree[2 * node] += lazy[node] * (mid - start + 1); lazy[2 * node] += lazy[node]; // 更新右子树 tree[2 * node + 1] += lazy[node] * (end - mid); lazy[2 * node + 1] += lazy[node]; // 清除当前节点的标记 lazy[node] = 0; } }4. 区间更新(Update)
void update(int node, int start, int end, int l, int r, int val) { if (r < start || end < l) // 完全无交集 return; if (l <= start && end <= r) { // 完全包含 tree[node] += val * (end - start + 1); // 更新当前节点 lazy[node] += val; // 标记延迟更新 return; } pushDown(node, start, end); // 下传标记 int mid = (start + end) / 2; update(2 * node, start, mid, l, r, val); // 更新左子树 update(2 * node + 1, mid + 1, end, l, r, val); // 更新右子树 tree[node] = tree[2 * node] + tree[2 * node + 1]; // 合并结果 }5. 区间查询(Query)
int query(int node, int start, int end, int l, int r) { if (r < start || end < l) // 完全无交集 return 0; if (l <= start && end <= r) // 完全包含 return tree[node]; pushDown(node, start, end); // 下传标记 int mid = (start + end) / 2; int leftSum = query(2 * node, start, mid, l, r); // 查询左子树 int rightSum = query(2 * node + 1, mid + 1, end, l, r); // 查询右子树 return leftSum + rightSum; // 合并结果 }
四、示例
1. 初始化
int n = 5; arr[1] = 1; arr[2] = 3; arr[3] = 5; arr[4] = 7; arr[5] = 9; build(1, 1, n);2. 区间更新
// 将区间 [2,4] 的所有值加 2 update(1, 1, n, 2, 4, 2);3. 区间查询
// 查询区间 [1,5] 的和 cout << query(1, 1, n, 1, 5) << endl; // 1 + 5 + 7 + 9 + 9 = 31
五、复杂度分析
操作 时间复杂度 空间复杂度 建树 O(n) 区间更新 O(log n) O(1) 区间查询
六、总结
延迟标记的核心思想是推迟更新,通过标记下传机制,将区间更新的时间复杂度优化到
O(log n)。它的实现需要:- 标记数组:记录每个节点的延迟更新操作。
- 标记下传:在查询和更新时,将标记下传给子节点。
- 区间更新:只更新当前节点,并标记延迟操作。
掌握延迟标记后,线段树可以高效处理动态区间更新和查询问题!
- 普通线段树:递归更新
-
@ 2025-2-1 9:47:52
线段树需要开 4N 的空间,主要是为了确保在最坏情况下有足够的空间存储所有节点。以下是详细解释:
一、线段树的空间需求
线段树是一棵完全二叉树,它的叶子节点存储原始数组的元素,而非叶子节点存储区间的统计值(如区间和、最大值等)。
1. 完全二叉树的性质
- 一棵高度为
h的完全二叉树,最多有2^h - 1个节点。 - 线段树的叶子节点数等于原始数组的长度
N,因此树的高度为h = ceil(log2(N)) + 1。
2. 最坏情况下的空间需求
- 当
N不是 2 的幂时,线段树并不是一棵满二叉树,最后一层会有空节点。 - 在最坏情况下,线段树的节点数会接近
2 * N,但实际需要更多空间来存储这些节点。
二、为什么是 4N?
1. 理论分析
- 线段树的高度为
h = ceil(log2(N)) + 1。 - 节点总数最多为
2^(h+1) - 1。 - 当
N不是 2 的幂时,2^(h+1) - 1会接近4N。
2. 实际例子
假设
N = 5:- 线段树的高度
h = ceil(log2(5)) + 1 = 4。 - 节点总数最多为
2^(4+1) - 1 = 31。 - 而
4N = 20,已经足够存储所有节点。
三、数学证明
-
满二叉树的情况:
- 当
N是 2 的幂时,线段树是一棵满二叉树。 - 节点总数为
2N - 1。
- 当
-
非满二叉树的情况:
- 当
N不是 2 的幂时,线段树的最后一层会有空节点。 - 节点总数最多为
2 * 2^ceil(log2(N)) - 1。 - 由于
2^ceil(log2(N)) < 2N,因此节点总数最多为4N - 1。
- 当
四、代码实现中的空间分配
在实际代码中,我们通常直接分配
4N的空间,以避免复杂的计算和边界问题。const int MAXN = 1e5; // 假设原始数组最大长度为 1e5 int tree[4 * MAXN]; // 线段树数组
五、总结
情况 节点总数 空间需求 N是 2 的幂2N - 12NN不是 2 的幂最多 4N - 14N因此,线段树开
4N的空间是为了覆盖最坏情况,确保有足够的空间存储所有节点,同时避免复杂的边界处理。 - 一棵高度为
-
@ 2025-2-1 9:24:40
二叉树的存储方式主要有两种:链式存储和顺序存储。以下是它们的详细说明和代码实现:
一、链式存储(最常用)
链式存储通过节点对象和指针来表示二叉树的结构。每个节点包含:
- 数据域(存储数据)
- 左指针(指向左孩子)
- 右指针(指向右孩子)
1. 节点定义
struct TreeNode { int val; // 数据域 TreeNode* left; // 左孩子指针 TreeNode* right; // 右孩子指针 // 构造函数 TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} };2. 创建二叉树
// 创建一棵简单的二叉树 // 1 // / \ // 2 3 // / \ // 4 5 TreeNode* createTree() { TreeNode* root = new TreeNode(1); root->left = new TreeNode(2); root->right = new TreeNode(3); root->left->left = new TreeNode(4); root->left->right = new TreeNode(5); return root; }3. 优点
- 灵活:适合动态变化的二叉树。
- 节省空间:只存储实际存在的节点。
4. 缺点
- 指针开销:每个节点需要额外的空间存储指针。
- 访问效率:访问父节点需要从根节点遍历。
二、顺序存储(基于数组)
顺序存储通过数组来表示二叉树,利用数组下标的关系来定位父子节点。
1. 存储规则
- 根节点存储在索引
0。 - 对于索引为
i的节点:- 左孩子索引:
2*i + 1 - 右孩子索引:
2*i + 2 - 父节点索引:
(i-1)/2
- 左孩子索引:
2. 示例
二叉树: 1 / \ 2 3 / \ 4 5 数组存储:[1, 2, 3, 4, 5, null, null]3. 代码实现
#include <vector> #include <iostream> using namespace std; // 顺序存储的二叉树 vector<int> tree = {1, 2, 3, 4, 5, -1, -1}; // -1 表示空节点 // 获取左孩子 int getLeftChild(int index) { int left = 2 * index + 1; return (left < tree.size() && tree[left] != -1) ? left : -1; } // 获取右孩子 int getRightChild(int index) { int right = 2 * index + 2; return (right < tree.size() && tree[right] != -1) ? right : -1; } // 前序遍历 void preOrder(int index) { if (index == -1 || tree[index] == -1) return; cout << tree[index] << " "; // 访问根节点 preOrder(getLeftChild(index)); // 访问左子树 preOrder(getRightChild(index)); // 访问右子树 } int main() { cout << "前序遍历结果:"; preOrder(0); // 从根节点开始遍历 return 0; }4. 优点
- 访问效率高:通过下标直接访问父子节点。
- 适合完全二叉树:空间利用率高。
5. 缺点
- 空间浪费:对于非完全二叉树,数组中会有大量空节点。
- 动态性差:插入和删除节点时需要移动大量元素。
三、两种存储方式的对比
特性 链式存储 顺序存储 存储结构 节点 + 指针 数组 空间效率 只存储实际节点 可能有空间浪费 访问效率 需要遍历指针 通过下标直接访问 适用场景 动态变化的二叉树 完全二叉树或静态二叉树 实现难度 较简单 需要处理空节点
四、选择存储方式的建议
- 链式存储:适合大多数场景,尤其是动态变化的二叉树。
- 顺序存储:适合完全二叉树或节点数量固定的场景。
五、扩展:其他存储方式
- 线索二叉树:在链式存储的基础上,利用空指针指向遍历顺序的前驱或后继节点。
- 孩子兄弟表示法:将二叉树转化为多叉树,每个节点存储第一个孩子和右兄弟的指针。
掌握这两种存储方式后,你可以根据具体问题选择最合适的实现方法!
-
@ 2025-2-1 9:18:56
二叉平衡树(Balanced Binary Tree)是一种特殊的二叉搜索树(BST),它通过自动调整树的结构,确保树的高度始终保持在 O(log n) 级别,从而保证插入、删除和查找操作的高效性。
一、为什么需要二叉平衡树?
普通的二叉搜索树(BST)在最坏情况下会退化成链表,导致操作的时间复杂度从 O(log n) 变成 O(n)。例如:
普通BST(退化成链表): 1 \ 2 \ 3 \ 4二叉平衡树通过旋转操作保持树的平衡,避免退化:
平衡的BST: 2 / \ 1 3 \ 4
二、常见的二叉平衡树
- AVL 树:通过严格的平衡因子(左右子树高度差不超过1)保持平衡。
- 红黑树:通过颜色标记和旋转操作,保持近似平衡。
- Splay 树:通过伸展操作,将最近访问的节点移动到根节点。
- Treap:结合二叉搜索树和堆的性质,通过随机优先级保持平衡。
三、AVL 树:严格平衡的代表
1. 核心思想
- 每个节点的平衡因子(Balance Factor)定义为:
左子树高度 - 右子树高度。 - 平衡因子必须为 -1、0 或 1,否则需要通过旋转调整。
2. 旋转操作
AVL 树通过四种旋转操作保持平衡:
- 左旋(Left Rotation):解决右子树过高。
- 右旋(Right Rotation):解决左子树过高。
- 左右旋(Left-Right Rotation):先左旋再右旋。
- 右左旋(Right-Left Rotation):先右旋再左旋。
示例:右旋
不平衡树: 3 / 2 / 1 右旋后: 2 / \ 1 3
四、红黑树:近似平衡的代表
1. 核心规则
- 每个节点是红色或黑色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。
- 如果一个节点是红色,则它的两个子节点都是黑色。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
2. 特点
- 红黑树通过颜色标记和旋转操作,保持树的高度近似平衡。
- 插入和删除操作的时间复杂度为 O(log n)。
五、C++ 实现:AVL 树
1. 节点定义
struct Node { int key; Node* left; Node* right; int height; // 节点高度 };2. 计算高度
int height(Node* node) { if (node == nullptr) return 0; return node->height; }3. 计算平衡因子
int getBalance(Node* node) { if (node == nullptr) return 0; return height(node->left) - height(node->right); }4. 右旋操作
Node* rightRotate(Node* y) { Node* x = y->left; Node* T2 = x->right; // 旋转 x->right = y; y->left = T2; // 更新高度 y->height = max(height(y->left), height(y->right)) + 1; x->height = max(height(x->left), height(x->right)) + 1; return x; }5. 插入操作
Node* insert(Node* node, int key) { // 1. 标准BST插入 if (node == nullptr) return new Node{key, nullptr, nullptr, 1}; if (key < node->key) node->left = insert(node->left, key); else if (key > node->key) node->right = insert(node->right, key); else return node; // 不允许重复键 // 2. 更新高度 node->height = 1 + max(height(node->left), height(node->right)); // 3. 获取平衡因子 int balance = getBalance(node); // 4. 根据平衡因子调整 // 左左情况 if (balance > 1 && key < node->left->key) return rightRotate(node); // 右右情况 if (balance < -1 && key > node->right->key) return leftRotate(node); // 左右情况 if (balance > 1 && key > node->left->key) { node->left = leftRotate(node->left); return rightRotate(node); } // 右左情况 if (balance < -1 && key < node->right->key) { node->right = rightRotate(node->right); return leftRotate(node); } return node; }
六、二叉平衡树的应用
- 数据库索引:B+ 树(基于平衡树)用于数据库索引。
- C++ STL:
std::map和std::set基于红黑树实现。 - 文件系统:文件目录结构常用平衡树组织。
七、总结
特性 普通 BST AVL 树 红黑树 平衡性 可能退化 严格平衡 近似平衡 插入/删除 O(n)(最坏情况) O(log n) 查找 适用场景 数据静态 频繁查找 频繁插入/删除 掌握二叉平衡树后,可以轻松应对动态数据的插入、删除和查找问题!
-
@ 2025-2-1 9:06:06
以下是C++线段树的详细教程,包含核心概念、代码实现和示例:
C++线段树教程
一、什么是线段树?
线段树(Segment Tree)是一种二叉树数据结构,用于高效处理区间查询和单点/区间更新操作,典型时间复杂度为O(log n)
常见应用场景:
- 区间求和/求积
- 区间最大值/最小值
- 区间GCD/LCM
- 区间覆盖统计
二、线段树结构
[1-8] / \ [1-4] [5-8] / \ / \ [1-2][3-4][5-6][7-8] ... ... ...三、核心操作实现
1. 数据结构准备
const int MAXN = 1e5; // 数据最大长度 int arr[MAXN]; // 原始数组 int tree[4*MAXN]; // 线段树数组(需要4倍空间)2. 建树(Build)
// 参数:当前节点,节点区间[left, right] void build(int node, int left, int right) { if (left == right) { tree[node] = arr[left]; return; } int mid = (left + right) / 2; int leftChild = 2 * node; int rightChild = 2 * node + 1; build(leftChild, left, mid); build(rightChild, mid+1, right); // 合并子节点结果(求和示例) tree[node] = tree[leftChild] + tree[rightChild]; }3. 区间查询(Query)
// 查询区间[qLeft, qRight] int query(int node, int curLeft, int curRight, int qLeft, int qRight) { // 当前区间与查询区间无交集 if (curRight < qLeft || curLeft > qRight) return 0; // 当前区间完全包含在查询区间内 if (qLeft <= curLeft && curRight <= qRight) return tree[node]; // 部分重叠,继续递归查询 int mid = (curLeft + curRight) / 2; int leftSum = query(2*node, curLeft, mid, qLeft, qRight); int rightSum = query(2*node+1, mid+1, curRight, qLeft, qRight); return leftSum + rightSum; }4. 单点更新(Update)
void update(int node, int curLeft, int curRight, int index, int newValue) { if (curLeft == curRight) { tree[node] = newValue; return; } int mid = (curLeft + curRight) / 2; if (index <= mid) update(2*node, curLeft, mid, index, newValue); else update(2*node+1, mid+1, curRight, index, newValue); tree[node] = tree[2*node] + tree[2*node+1]; }四、使用示例
int main() { int n = 6; arr[1] = 1; arr[2] = 3; arr[3] = 5; arr[4] = 7; arr[5] = 9; arr[6] = 11; // 建树(根节点为1,区间[1,6]) build(1, 1, n); // 查询区间[2,5]的和 cout << query(1, 1, 6, 2, 5) << endl; // 3+5+7+9=24 // 更新arr[3]为10 update(1, 1, 6, 3, 10); // 再次查询 cout << query(1, 1, 6, 2, 5) << endl; // 3+10+7+9=29 return 0; }五、变种实现
区间最小值版本
// 修改建树时的合并操作 tree[node] = min(tree[leftChild], tree[rightChild]); // 修改查询时的合并操作 return min(leftMin, rightMin); // 初始化时叶节点赋值为arr[i]六、注意事项
- 数组大小:线段树数组需要开4倍原始数据大小
- 索引起点:通常使用1-based索引更方便计算
- 区间划分:注意处理mid的归属问题(左闭右开或全闭区间)
- 延迟标记:进阶实现需要添加lazy propagation处理区间更新
七、复杂度分析
操作 时间复杂度 空间复杂度 建树 O(n) 查询 O(log n) O(1) 更新 掌握线段树后,可以轻松解决LeetCode上多种区间操作问题,如:307. 区域和检索 - 数组可修改、715. Range 模块等经典题目。
- 1